7 Tips to Achieve High-Availability(HA) For Your Maven Repository
Every company loves HA, simply because it makes their services available and more reliable at any given time. Here are seven tips to achieve HA.
Join the DZone community and get the full member experience.
Join For FreeCloud Computing has emerged as a novel technology today. Every company is a software company today, and it is evident that no company can service without using the power of cloud computing. The cloud is seen as a conceptual layer on the Internet, making all available software and hardware resources transparent, rendering them accessible through a well-defined interface.
As the companies are increasingly relying on these cloud computing services to be always stable and accessible whenever their customers need them, the services and applications' downtime is highly unacceptable. In this article, we will be discussing the concepts related to high availability (HA), what it is, how it works, and how companies can take advantage of this.
What is high availability (HA)?
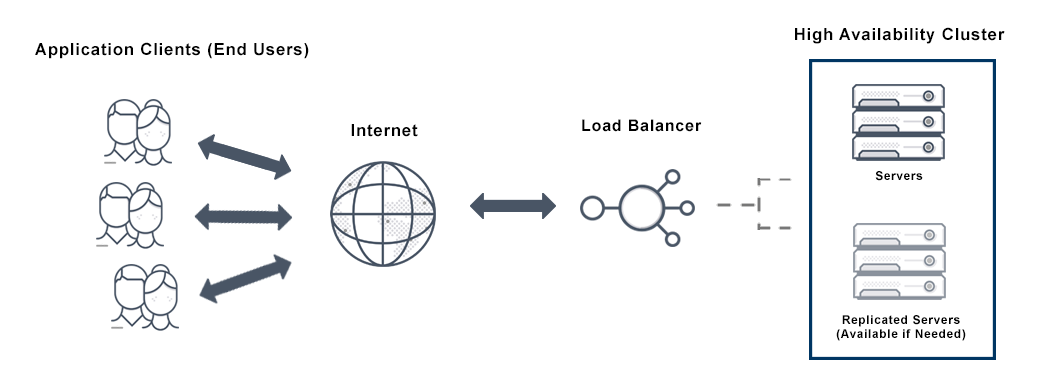
Image source: Avi Networks
When it comes to measuring cloud computing availability, several factors come into the picture - recovery time, scheduled and unscheduled maintenance periods, unanticipated loads, increased usage, etc. Hence, availability as a whole is expressed as a percentage of uptime defined by service level agreements (SLAs). HA embodies the idea of any time and anywhere access to services. It assures a high-level operational performance for a given period without any outages or downtime.
In general, a high availability system works by having more components to provide a safety buffer, by performing regular checks to ensure that each component works correctly and, in case of failure, by replacing it with the one that works.
Why high availability (HA)?
Every company loves HA, simply because it makes their services available and more reliable at any given time. Many unexpected events can occur and can bring down the systems and servers. Even the highly robust systems can go down. Hence, it is very important to reduce the service interruptions, outages, and downtime with HA. Highly available systems can automatically recover the loss and from server failures. HA becomes too important from the company's business perspective. The services going down are not a good thing, customers get angry, which can even let loyal customers find alternatives and opt for competitor services. Downtime and outages today mean loss of revenue. This is how important HA is.
The following table provides “availability classes” based on associated downtime amounts (courtesy of Zimory)
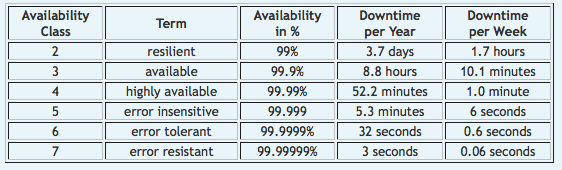
Image source: Jim Kaskade
Traits of a highly available infrastructure
A highly available infrastructure has these traits listed below,
- No single points of failure
- Hardware redundancy
- Reliable crossover
- Software and application redundancy
- Data redundancy
- Self-monitoring for failure
How to achieve high availability?
1. Scaling up and down
In companies, high availability is achieved by scaling the servers up or down depending on the application server's load and availability. It is done mostly outside the application at the server level.
How scaling works here?
There are two types when it comes to scaling. Let me describe it in simple terms.
Horizontal Scaling: This is achieved by adding more machines into your pool of resources.
Vertical Scaling: This is achieved by adding more power (CPU, RAM) to an existing device/machine.
2. Implementing multiple application servers
Overburdened servers may crash and cause an outage; it is advisable to deploy applications over multiple servers to keep the applications running all the time. It creates a sense of being always operational.
3. Monitoring
A well-integrated monitoring tool provides insight into an application's performance and its current function; it also monitors error-rates if exceeded a predefined threshold. For example, a shopping site's engineering team can monitor a payment gateway so that if credit/debit card transactions exceed a 15% failure rate, the team automatically gets an alert on self-healing tasks.
4. Load Balancing
A load balancer is something that acts as a reverse proxy and distributes the application traffic across a number of servers. This approach is used to increase the capacity and reliability of the applications.
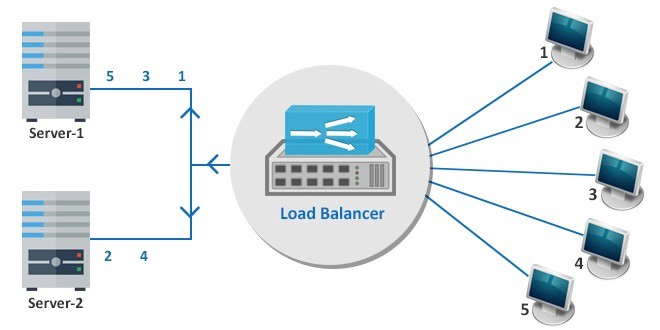
Image credits: Google - used here
High availability load balancing (HALB) is important in stopping potentially catastrophic disasters and component failures. Using primary and secondary load balancers to automatically distribute workloads across your data centers. This redundancy in both your load balancers and servers guarantees near-continuous application delivery.
5. Failover setup
In the same location, relying on more than one element poses a risk; even one database server poses a risk. It gives way to a single point of failure (SPoF) if any component anywhere along that chain breaks. One way to reduce the risk of SPoF is by implementing as much network redundancy as possible.
If you are running your own infrastructure, you should consider many infrastructure areas to ensure they all have a decent redundancy setup.
6. Multi-region deployments
When it comes to cloud environments, systems are deployed in units and are referred to as regions. A region can be defined as a data center, or it may be consisting of a set of data centers located somewhat close to each other. Then there comes a more granular unit inside of the regions and is known as availability zone. So, each availability zone is a single data center within one region.
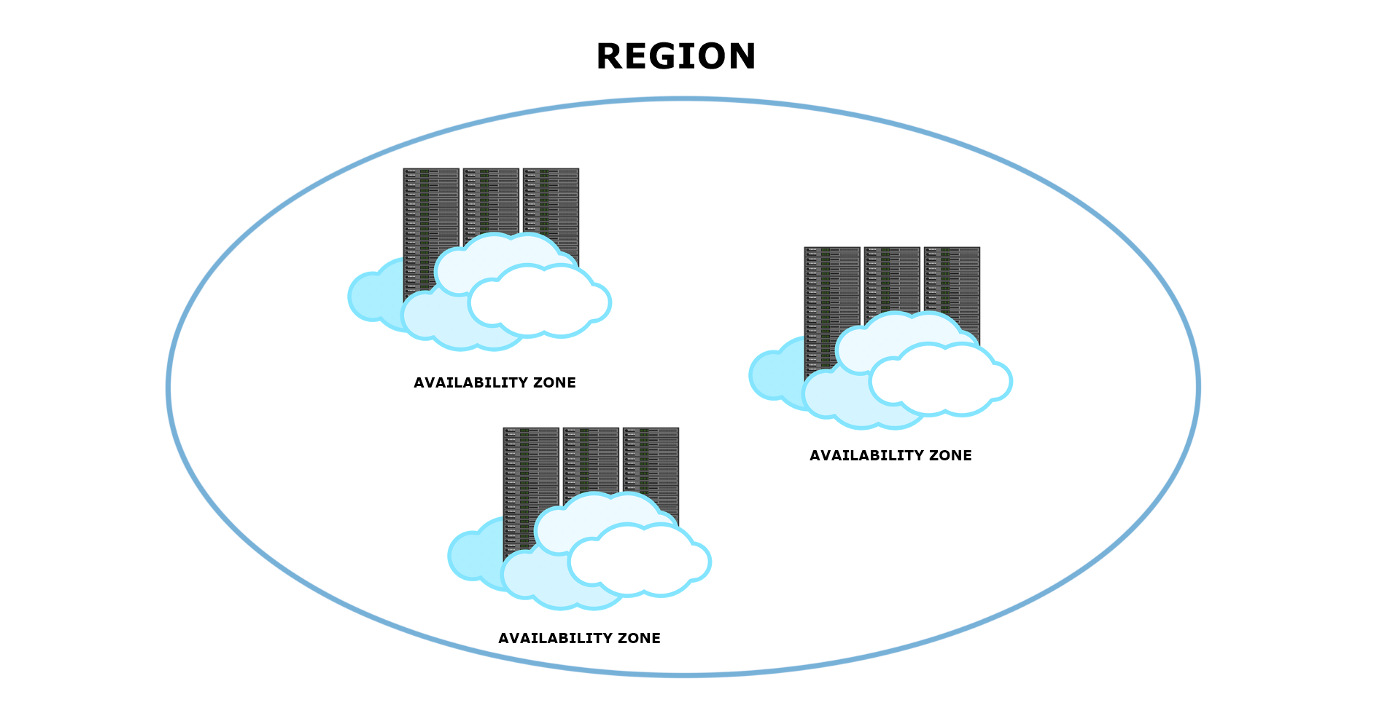
Image credits: camelia_sasquana on Pixabay
Region failure becomes more resistant when the system is deployed in different regions and/or several availability zones. It adds more redundancy to the architecture.
7. Clustering techniques
Clustering techniques are generally used to improve and increase the performance and availability of a complex system. A cluster is usually designed as a redundant set of services rendering the same set of functionalities and capabilities.
HA clusters or a failover cluster is nothing but a highly redundant multiple server network that makes sure the critical server applications to run 24/7 throughout the year. By chance, in rare scenarios, if one server in a high availability cluster collapses, the mission-critical app & services are immediately restarted on another server just the moment the flaw is detected.
Note: With an Enterprise license, Artifactory supports a High Availability network configuration with a cluster of 2 or more active/active, read/write Artifactory servers on the same Local Area Network (LAN). This offers a level of stability and availability that is unmatched in the industry.
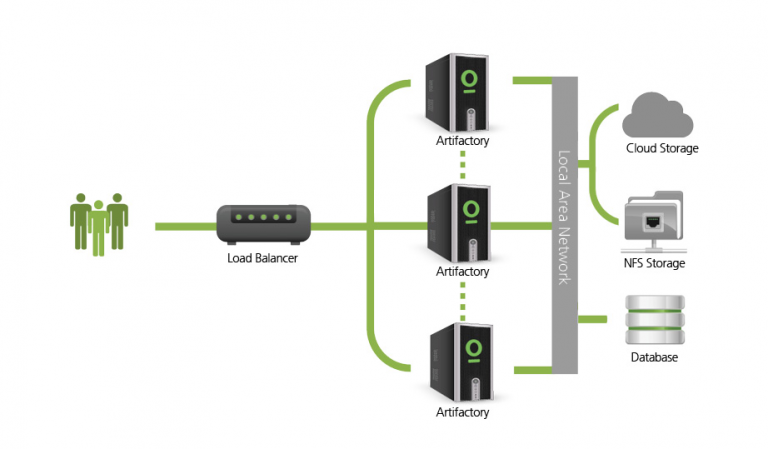
Image credits: JFrog
Amazon's approach to high-availability deployment
Continuous-delivery failures usually lead to reduced service availability and awful customer experiences that can hit your business really hard. To achieve zero deployment failures, Amazon's development teams have implemented some strategies for the end-to-end release process.
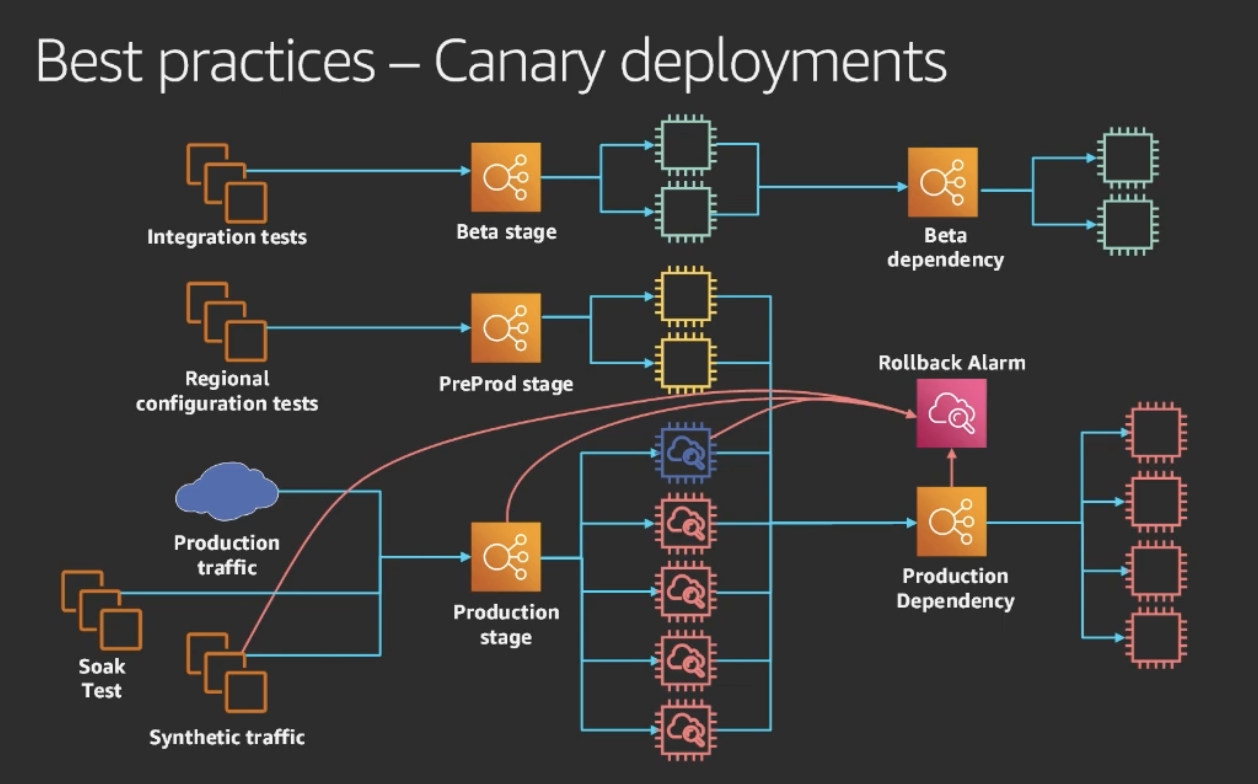
Listing here the learnings from Amazon's development team while dealing with high-availability deployments,
Integration testing: They expect all service teams to implement integration testing in their pipelines.
Pre-production testing: The pre-production fleet only has production dependencies. The testing here is to make sure all the configuration they are about to roll out to the production is configured correctly.
Canary deployment: It is a type of deployment to a single instance of a production fleet. The instances here now slowly take the production traffic. The purpose of the canary deployment is to limit the impact of the production deployment in the production fleet.
Rollback alarms: This is employed to alarm the customers' experiences.
In this video, you can learn more about the continuous-delivery practices that Amazon invented that help raise the bar and prevent costly deployment failures.
HA architecture
Let's take an example of Artifactory to see how HA architecture looks.
The HA architecture consists of 3 building blocks: load balancer, application(s), and common resources.
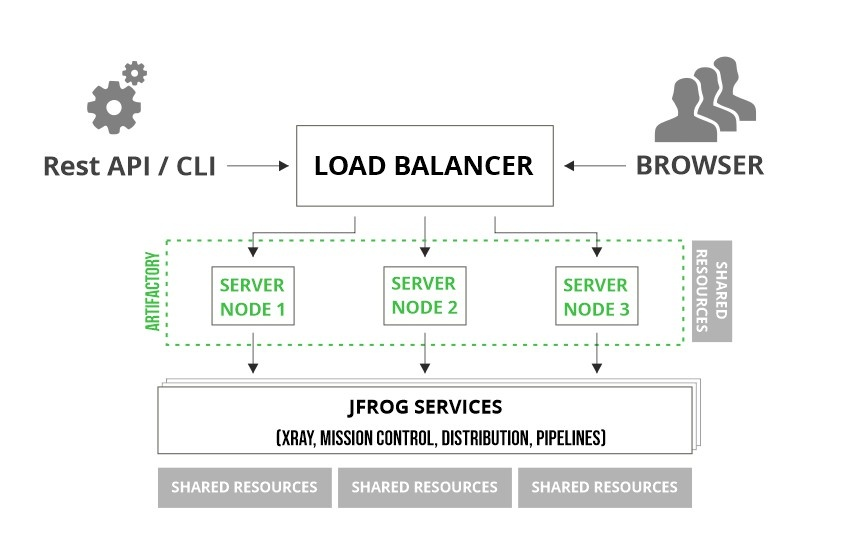
Image credits: JFrog
Load Balancer
The load balancer is the entry point and optimally distributes requests to the nodes in your system.
Application
An application running in HA mode represents a cluster of two or more nodes that share common resources. Each cluster node runs all microservices.
Common Resources
Each service requires a set of common resources. The resources vary per service but typically include at least one database.
When it comes to Artifactory HA, it was designed to scale. Artifactory allows you to start with minimal setup and scales as you need and does not enforce growth limitations. JFrog provides consistent performance and exceptional stability, starting from a small number of nodes to have HA, as discussed before. This also comes with support for rolling upgrades. JFrog makes it easy to monitor what's happening inside your cluster with built-in integration of Splunk, thus having a comprehensive ecosystem is a must for a proper HA.
JFrog HA works with local, NFS or object storage, and includes live failover and non-disruptive production upgrades. All supported Artifactory package types are also supported in HA mode.
As Artifactory supports a High Availability configuration with a cluster of 2 or more active/ active Artifactory servers on the same Local Area Network.
This redundant network architecture has several benefits:
- No single-point-of-failure
Your system can continue to operate as long as at least one of the Artifactory nodes is operational. This maximizes your uptime and can take it to levels of up to “five nines” availability.
- Accommodate larger load bursts
With horizontal server scalability, you can increase your capacity with no compromise to performance and meet any increasing load requirements as your organization grows.
- Multiple server architecture
Artifactory HA lets you perform most maintenance tasks with no system downtime.
[Credit source: 8 Reasons for DevOps to Use a Binary Repository Manager]
Mission-critical systems of any firm should be deployed in a High Availability configuration to enhance both stability and reliability. In a High Availability configuration, there will not be any single-point-of-failure. The redundancy is highly maintained through the redundant nodes in a HA configuration, and hence the system continues to operate seamlessly and uninterrupted.
Take a look at this HA comparison chart by different companies.
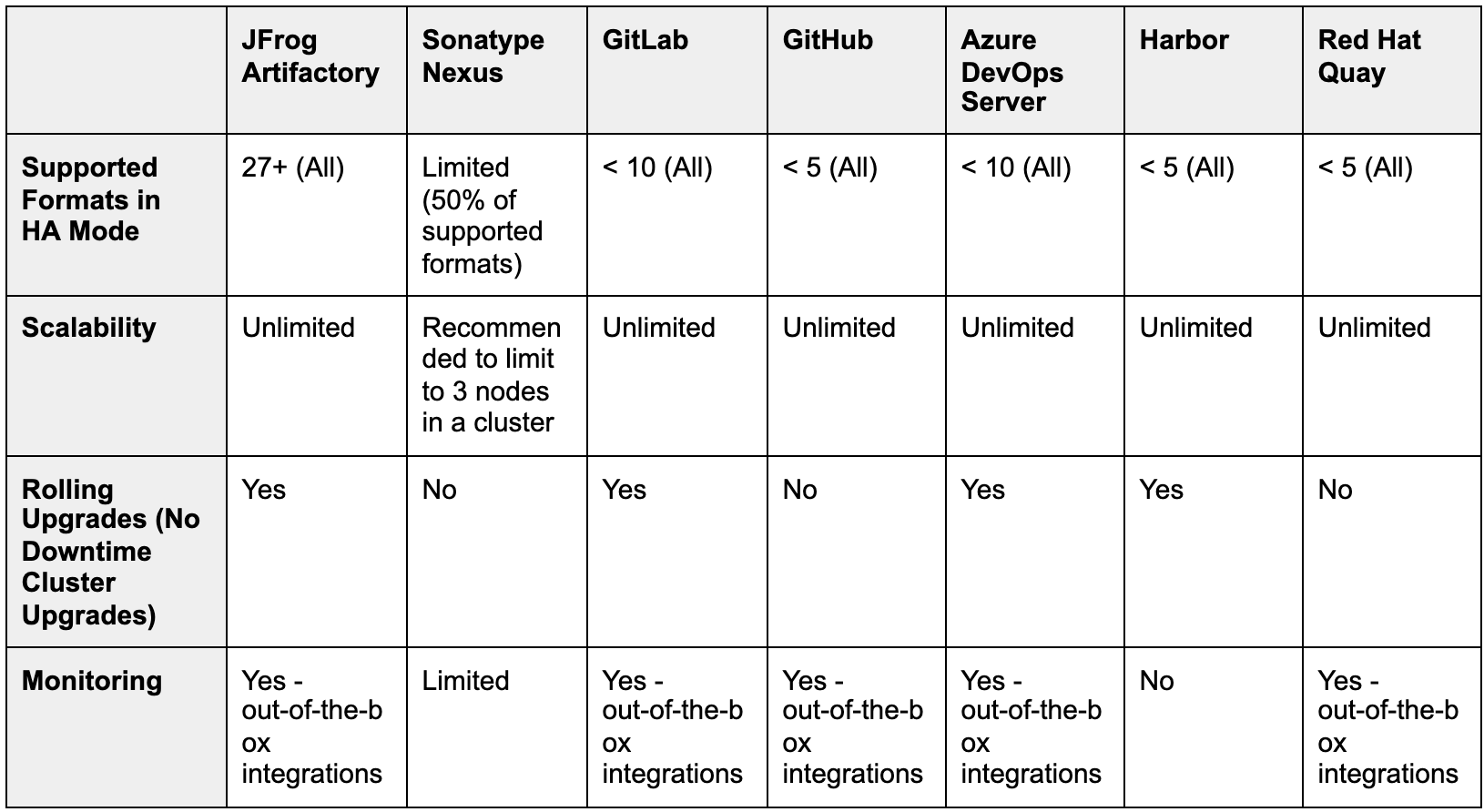
Published at DZone with permission of Pavan Belagatti, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments