7 Query Strategies for Navigating Knowledge Graphs With NebulaGraph and LlamaIndex
This article compares seven query engines by building a knowledge graph with NebulaGraph and LlamaIndex to better understand their use cases.
Join the DZone community and get the full member experience.
Join For FreeThere has been a lot of buzz around developing RAG (Retrieval Augmented Generation) pipelines powered by LLMs and Knowledge Graphs (KG) lately. In this article, let’s take a close look at Knowledge Graphs by building an RAG pipeline for the Philadelphia Phillies using LlamaIndex and NebulaGraph.
Use Case
We will use Knowledge Graph, specifically the open source NebulaGraph, to query information on the Philadelphia Phillies, the Major League Baseball team based in Philadelphia. My whole family are big fans of the Phillies!
We will use the Wikipedia page of the Philadelphia Phillies as one of our source documents. In addition, in light of the recent standing ovation event Philly fans organized for one of our favorite players, Trea Turner, we will use a YouTube video that comments on this great event as another part of our source documents.
Our high-level architectural diagram looks like this:
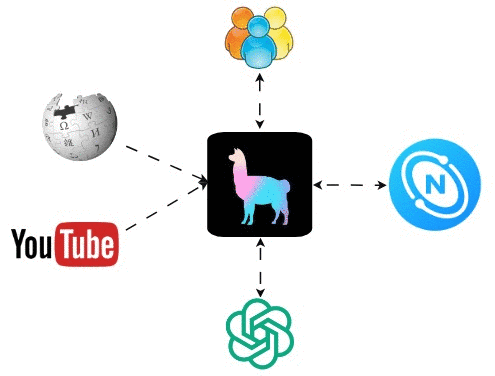
For those already familiar with Knowledge Graph and NebulaGraph, feel free to skip to the “Detailed Implementation” section. For those new to NebulaGraph, read on.
Knowledge Graph (KG)
A knowledge graph is a knowledge base that uses a graph-structured data model or topology to integrate data. It is a way to represent information about real-world entities and their relationships to each other. Knowledge graphs are often used to power search engines, recommendation systems, social networks, etc.
Main Components
Knowledge graphs are typically composed of two main components:
1. Vertex/Node: represents entities or objects in the domain of knowledge. Each node corresponds to a unique entity and is identified by a unique identifier. For example, in a knowledge graph about the Philadelphia Phillies, nodes could have values such as “Philadelphia Phillies” and “Major League Baseball.”
2. Edge: represents the relationship between two nodes. For example, an edge “compete in” might connect the node for “Philadelphia Phillies” to the node for “Major League Baseball.”
Triplet
A triplet is a basic unit of data in the graph. It consists of three parts:
1. Subject: the node that the triplet is about.
2. Object: the node that the relationship points to.
3. Predicate: the relationship between the subject and the object.
In the following triplet example, “Philadelphia Phillies” is the subject, “compete in” is the predicate, and “Major League Baseball” is the object.
(Philadelphia Phillies)--[compete in]->(Major League Baseball)
A Knowledge Graph database can efficiently store and query complex graph data by storing triplets.
Cypher
Cypher is a declarative graph query language that is supported by Knowledge Graph. With Cypher, we tell Knowledge Graph what we want but not how to do it. This makes Cypher queries more readable and maintainable. Cypher is easy to learn, use, and expressive enough to handle complex graph queries.
Here is an example of a simple Cypher query:
%%ngql
MATCH (p:`entity`)-[e:relationship]->(m:`entity`)
WHERE p.`entity`.`name` == 'Philadelphia Phillies'
RETURN p, e, m;This query will match all of the entities associated with the Philadelphia Phillies.
NebulaGraph
NebulaGraph is a graph database that is open-source, distributed, and capable of handling large-scale graphs with trillions of edges and vertices, with millisecond latency. Large companies widely use it for various applications, including social media, recommendation systems, fraud detection, etc.
Installation
For our Phillies RAG pipeline, we will need to install NebulaGraph locally. One of the quickest ways to install NebulaGraph locally is through Docker Desktop. The detailed instructions can be found in the NebulaGraph’s documentation.
For those new to NebulaGraph, check out NebulaGraph’s detailed documentation to learn more about it.
Detailed Implementation
There is a comprehensive guide on knowledge graph RAG development, thoughtfully put together by Wey Gu, Chief Evangelist at NebulaGraph, and the team at LlamaIndex. I recommend you check out the details of that guide, which I have learned a great deal from.
Based on what we’ve learned from that guide, let’s walk through the detailed steps to build our Phillies RAG pipeline using LlamaIndex, NebulaGraph, and GPT-3.5.
Refer to my GitHub repo for the complete Jupyter notebook for our Phillies’ RAG pipeline.
Step 1: Installation and Configuration
In addition to LlamaIndex, we need to install a few libraries:
- ipython-ngql: a Python package that enhances your ability to connect to NebulaGraph from your Jupyter Notebook or iPython.
- nebula3-python: a Python client for connecting to and managing the NebulaGraph database.
- pyvis: a library that enables quick generation of visual network graphs with minimal Python code.
- networkx: a Python library for studying graphs and networks.
- youtube_transcript_api: a Python API that lets you get the transcripts/subtitles for a YouTube video.
%pip install llama_index==0.8.33 ipython-ngql nebula3-python pyvis networkx youtube_transcript_api>Let’s also set our OpenAI API key and configure the logging for our app:
import os
import logging
import sys
os.environ["OPENAI_API_KEY"] = "sk-####################"
logging.basicConfig(stream=sys.stdout, level=logging.INFO)Step 2: Connect to NebulaGraph and Set Up a New Space
Assume you have NebulaGraph installed locally; we can now connect to it from your Jupyter notebook (Note: don’t try connecting to your local NebulaGraph from Google Colab; it won’t work for obvious reasons :-))
Follow the code snippet below to:
- Connect to your local NebulaGraph (its default password is nebula).
- Create a new space named phillies_rag.
- Create tag, edge, and tag index in the new space.
os.environ["GRAPHD_HOST"] = "127.0.0.1"
os.environ["NEBULA_USER"] = "root"
os.environ["NEBULA_PASSWORD"] = "nebula"
os.environ["NEBULA_ADDRESS"] = "127.0.0.1:9669"
%reload_ext ngql
connection_string = f"--address {os.environ['GRAPHD_HOST']} --port 9669 --user root --password {os.environ['NEBULA_PASSWORD']}"
%ngql {connection_string}
%ngql CREATE SPACE IF NOT EXISTS phillies_rag(vid_type=FIXED_STRING(256), partition_num=1, replica_factor=1);
%%ngql
USE phillies_rag;
CREATE TAG IF NOT EXISTS entity(name string);
CREATE EDGE IF NOT EXISTS relationship(relationship string);
%ngql CREATE TAG INDEX IF NOT EXISTS entity_index ON entity(name(256));With our new space created in NebulaGraph, let’s construct our NebulaGraphStore. See the code snippet below:
from llama_index.storage.storage_contextimportStorageContext
from llama_index.graph_storesimportNebulaGraphStore
space_name = "phillies_rag"
edge_types, rel_prop_names = ["relationship"], ["relationship"]
tags = ["entity"]
graph_store = NebulaGraphStore(
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)Step 3: Load Data and Create a KG Index
Time to load our data. Our source data comes from the Philadelphia Phillies Wikipedia page and a YouTube video on the standing ovation event Trea Turner received in August 2023.
To save time and cost, we first check in our local storage_context to load the KG index. If it exists, we load the index. If it doesn’t exist, such as when accessing the app the first time, we need to load the two source documents, from which we build the KG index and then persist the doc store, index store, and vector store in the local storage_graph directory at the project root.
from llama_index import (
LLMPredictor,
ServiceContext,
KnowledgeGraphIndex,
)
from llama_index.graph_stores import SimpleGraphStore
from llama_index import download_loader
from llama_index.llms import OpenAI
# define LLM
llm = OpenAI(temperature=0.1, model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=512)
from llama_index import load_index_from_storage
from llama_hub.youtube_transcript import YoutubeTranscriptReader
try:
storage_context = StorageContext.from_defaults(persist_dir='./storage_graph', graph_store=graph_store)
kg_index = load_index_from_storage(
storage_context=storage_context,
service_context=service_context,
max_triplets_per_chunk=15,
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
verbose=True,
)
index_loaded = True
except:
index_loaded = False
if not index_loaded:
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
wiki_documents = loader.load_data(pages=['Philadelphia Phillies'], auto_suggest=False)
print(f'Loaded {len(wiki_documents)} documents')
youtube_loader = YoutubeTranscriptReader()
youtube_documents = youtube_loader.load_data(ytlinks=['https://www.youtube.com/watch?v=k-HTQ8T7oVw'])
print(f'Loaded {len(youtube_documents)} YouTube documents')
kg_index = KnowledgeGraphIndex.from_documents(
documents=wiki_documents + youtube_documents,
storage_context=storage_context,
max_triplets_per_chunk=15,
service_context=service_context,
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
include_embeddings=True,
)
kg_index.storage_context.persist(persist_dir='./storage_graph')A few things to point out in the KG index construction:
- max_triplets_per_chunk: the maximum number of triplets to extract in a chunk. Let’s give it 15, which hopefully should cover most, if not all, content in each chunk.
- include_embeddings: specify whether the embeddings of the data should be included when creating the knowledge graph index. Embeddings are a way of representing text data as vectors that capture the semantic meaning of the data. They are often used to enable the models to understand the semantic similarity between different pieces of text. When include_embeddings=True is set, the KnowledgeGraphIndex will include these embeddings in the index. This can be useful when you want to perform a semantic search on the Knowledge Graph, as the embeddings can be used to find nodes and edges that are semantically similar to the query.
Step 4: Run a Query To Explore NebulaGraph
Let’s now run a simple query.
Tell me about some of the facts of the Philadelphia Phillies.
query_engine = kg_index.as_query_engine()
response = query_engine.query("Tell me about some of the facts of Philadelphia Phillies.")
display(Markdown(f"<b>{response}</b>"))We get the following response, a pretty good summary of the Philadelphia Phillies from its Wikipedia page!

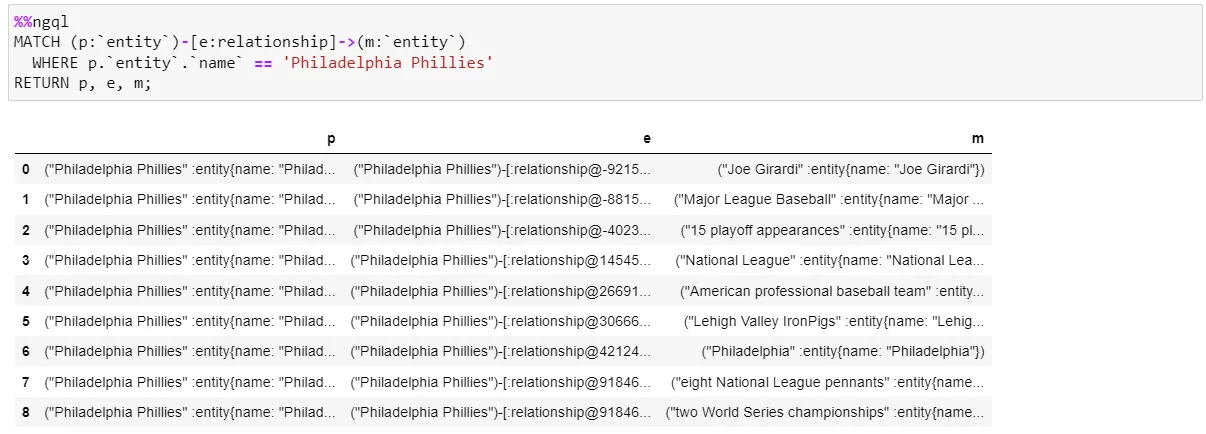
Querying in Cypher, we come up with the following:
%%ngql
MATCH (p:`entity`)-[e:relationship]->(m:`entity`)
WHERE p.`entity`.`name` == 'Philadelphia Phillies'
RETURN p, e, m;This query will match all of the entities associated with the Philadelphia Phillies. The query results will be a list of all the entities associated with the Phillies, their relationships to the Phillies, and, of course, the Phillies entity. Let’s execute this Cypher query in our Jupyter Notebook.
Nine rows were returned in the response:
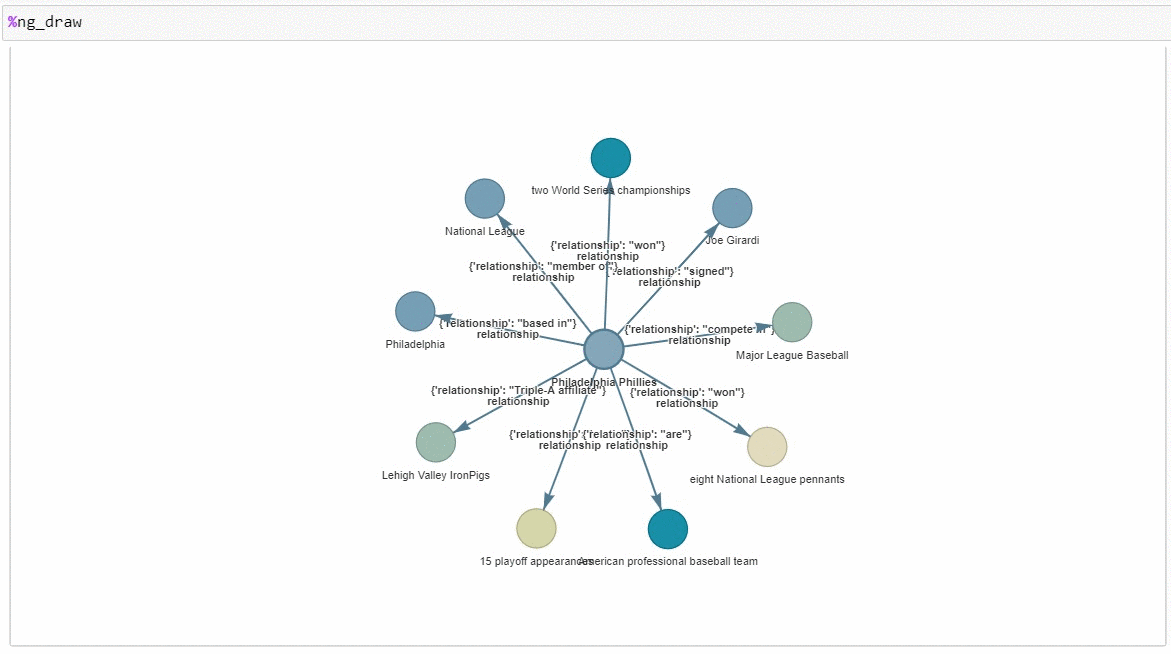
Next, run ng_draw, a command from the ipython-ngql package that can render the results of a NebulaGraph query in a single-file HTML file; we get the following graph. Centering around the “Philadelphia Phillies” node, it spins out nine other nodes, each representing one of the row items in the Cypher query results above. Connecting each node to the center node is the edge, the relationship between the two nodes.
You can drag and drop the nodes to manipulate the graph. It is pretty cool!
Now that we have the basics of NebulaGraph down let’s dive a little deeper.
Step 5: Explore Seven Query Methods
Based on our KG index, let’s query our Knowledge Graph with different methods and observe their results.
Query Method 1: KG Vector-Based Entity Retrieval
query_engine = kg_index.as_query_engine()This method looks up KG entities with vector similarity, pulls in linked text chunks, and optionally explores relationships. It is the default way LlamaIndex’s KG query engines are built based on the index. It is pretty simple and out-of-the-box, and no additional parameters are needed.
Query Method 2: KG Keyword-Based Entity Retrieval
kg_keyword_query_engine = kg_index.as_query_engine(
# setting to false uses the raw triplets instead of adding the text from the corresponding nodes
include_text=False,
retriever_mode="keyword",
response_mode="tree_summarize",
)This query engine uses keywords from the query to retrieve relevant KG entities, pulls in linked text chunks, and optionally explores relationships to pull in more context. It is configured to use a keyword-based retriever by specifying parameter retriever_mode="keyword."
- include_text=False: the query engine will only use the raw triplets for queries; no text from the corresponding nodes will be included in the response.
- response_mode="tree_summarize": the response will be a summary of the tree structure of the knowledge graph. The tree will be constructed recursively, with the query at the root node and the most relevant answers at the leaf nodes. The tree_summarize response mode is useful for summarization tasks, such as providing a high-level overview of a topic or answering a question that requires a comprehensive response. It can also generate more complex responses, such as providing a list of reasons why something is true or explaining the steps involved in a process.
Query Method 3: KG Hybrid Entity Retrieval
kg_hybrid_query_engine = kg_index.as_query_engine(
include_text=True,
response_mode="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=3,
explore_global_knowledge=True,
)By specifying embedding_mode="hybrid," this query engine is configured to use a hybrid approach — both vector-based entity retrieval and keyword-based entity retrieval for retrieving information from the knowledge graph, with deduplication. The KG hybrid entity retrieval uses keywords to find relevant triplets. Then, it also uses vector-based entity retrieval to find similar triplets based on semantic similarity. So, in essence, the `hybrid` mode combines both keyword search and semantic search, leveraging the strengths of both methods to improve the accuracy and relevance of the search results.
- include_text=True: the query engine will use text from the corresponding nodes in the response.
- similarity_top_k=3: it will retrieve the top three most similar results based on the embeddings. Feel free to adjust this value based on your use case.
- explore_global_knowledge=True: specify whether the query engine should consider the global context of the knowledge graph when retrieving information. When explore_global_knowledge=True is set, the query engine will not limit its search to the local context (i.e., the immediate neighbors of a node) but will also consider the broader, global context of the knowledge graph. This can be useful when you want to retrieve information that is not directly connected to the query but is relevant in the larger context of the knowledge graph.
The main difference between keyword-based entity retrieval and hybrid entity retrieval is the method we use to retrieve information from the knowledge graph: keyword-based entity retrieval uses a keyword-based approach, while hybrid entity retrieval uses a hybrid approach that combines both embeddings and keywords.
Query Method 4: Raw Vector Index Retrieval
This method does not deal with knowledge graph at all. It is based on the vector index. Let’s first construct the vector index from the documents and then build a vector query engine from the vector index.
vector_index = VectorStoreIndex.from_documents(wiki_documents + youtube_documents)
vector_query_engine = vector_index.as_query_engine()Query Method 5: Custom Combo Query Engine (Combo of KG Retriever and Vector Index Retriever)
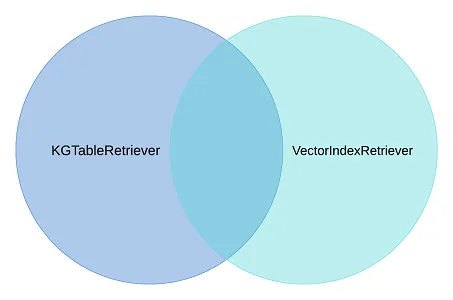
LlamaIndex has crafted a CustomRetriever. You can see what it looks like in the code below. It performs a knowledge graph search and a vector search. The default mode OR warrants the union of both searches, resulting in search results containing the best of both worlds, with deduplication:
- Nuanced details from the knowledge graph search (KGTableRetriever).
- Semantic similarity search details from the vector index search (VectorIndexRetriever).
from llama_index import QueryBundle
from llama_index.schema import NodeWithScore
from llama_index.retrievers import BaseRetriever, VectorIndexRetriever, KGTableRetriever
from typing import List
class CustomRetriever(BaseRetriever):
def __init__(
self,
vector_retriever: VectorIndexRetriever,
kg_retriever: KGTableRetriever,
mode: str = "OR",
) -> None:
"""Init params."""
self._vector_retriever = vector_retriever
self._kg_retriever = kg_retriever
if mode not in ("AND", "OR"):
raise ValueError("Invalid mode.")
self._mode = mode
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""Retrieve nodes given query."""
vector_nodes = self._vector_retriever.retrieve(query_bundle)
kg_nodes = self._kg_retriever.retrieve(query_bundle)
vector_ids = {n.node.node_id for n in vector_nodes}
kg_ids = {n.node.node_id for n in kg_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in kg_nodes})
if self._mode == "AND":
retrieve_ids = vector_ids.intersection(kg_ids)
else:
retrieve_ids = vector_ids.union(kg_ids)
retrieve_nodes = [combined_dict[rid] for rid in retrieve_ids]
return retrieve_nodes
from llama_index import get_response_synthesizer
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.retrievers import VectorIndexRetriever, KGTableRetriever
# create custom retriever
vector_retriever = VectorIndexRetriever(index=vector_index)
kg_retriever = KGTableRetriever(
index=kg_index, retriever_mode="keyword", include_text=False
)
custom_retriever = CustomRetriever(vector_retriever, kg_retriever)
# create response synthesizer
response_synthesizer = get_response_synthesizer(
service_context=service_context,
response_mode="tree_summarize",
)
custom_query_engine = RetrieverQueryEngine(
retriever=custom_retriever,
response_synthesizer=response_synthesizer,
)Query Method 6: KnowledgeGraphQueryEngine
So far, we’ve explored different query engines built with indexes. Now, let’s look at another Knowledge Graph query engine crafted by LlamaIndex — KnowledgeGraphQueryEngine. See the code snippet below:
query_engine = KnowledgeGraphQueryEngine(
storage_context=storage_context,
service_context=service_context,
llm=llm,
verbose=True,
)The KnowledgeGraphQueryEngine is a query engine that allows us to query a knowledge graph using natural language. It uses an LLM to generate Cypher queries, which are then executed on the knowledge graph. This makes it possible to query a knowledge graph without learning Cypher or any other query language.
KnowledgeGraphQueryEngine takes in storage_context, service_context, and llm and builds a query engine for knowledge graphs with NebulaGraphStore as the storage_context.graph_store.
Query Method 7: KnowledgeGraphRAGRetriever
KnowledgeGraphRAGRetriever is a RetrieverQueryEngine in LlamaIndex that performs Graph RAG queries on a knowledge graph. It takes a question or task as input and performs the following steps:
- Searches for related entities in the knowledge graph using keyword extraction or embedding.
- Gets a subgraph of those entities from the knowledge graph, with a default depth of 2.
- Build a context based on the subgraph.
A downstream task, such as an LLM, can then use the context to generate a response. See the code snippet below to construct a KnowledgeGraphRAGRetriever:
graph_rag_retriever = KnowledgeGraphRAGRetriever(
storage_context=storage_context,
service_context=service_context,
llm=llm,
verbose=True,
)
kg_rag_query_engine = RetrieverQueryEngine.from_args(
graph_rag_retriever, service_context=service_context
)Now that we have a good understanding of all seven query methods. Let’s test them out with a set of questions.
Test the Seven Query Methods With Three Questions
Question 1: Tell Me About Bryce Harper
See a list of responses from the seven query methods below. They’re color-coded based on the query engine used.

Here is my observation:
- The KG vector-based entity retrieval, keyword-based entity retrieval, KnowledgeGraphQueryEngine, and KnowledgeGraphRAGRetriever, all returned the key facts about the subject we are trying to query — Bryce Harper’s key facts only — with no elaboration on the details.
- The KG hybrid entity retrieval, raw vector index retrieval, and custom combo query engine all returned a decent amount of information related to our subject, mainly because they could access the query embeddings.
- The raw vector index retrieval returned a response faster (~3 seconds) than the other KG query engines (4+ seconds). The KG hybrid entity retrieval was the slowest (~10 seconds).
Question 2: How Did the Standing Ovation Trey Turner Received Change His Season?
This question was purposely designed based on the content from the YouTube video, which talked exclusively about this standing ovation event Philly fans showed support for Trea Turner (YouTube transcribed his first name as “Trey” instead of “Trea,” thus we use “Trey” in the question). See the list of responses for the seven query methods below:

Here’s my observation:
- The KG vector-based entity retrieval returned a perfect response, with all supporting facts and detailed statistics showing how Philly fans helped Trea Turner turn his season around. The reason is that all those facts are stored in NebulaGraph, loaded from the YouTube video transcript.
- The KG keyword-based entity retrieval returned a very brief response no supporting facts.
- The KG hybrid entity retrieval returned good response, although lacking in detailed factual information on Turner’s performance after the standing ovation. Consider this response slightly inferior to that returned from the KG vector-based entity retrieval.
- The raw vector index retrieval and custom combo query engine returned decent responses, with more detailed factual information, but not as complete as the response from the KG vector-based entity retrieval. Why didn’t the custom combo query engine respond better than the KG vector-based entity retrieval? The main reason I can think of is that the Wikipedia page contains no information related to Turner’s standing ovation event. Only the YouTube video does. The YouTube video exclusively talked about the standing ovation event, which was all loaded in the knowledge graph. The knowledge graph has ample relevant content to return a solid response. Raw vector index retrieval or custom combo query engine didn’t have more content to add.
- KnowledgeGraphQueryEngine returned the following syntax error. The root cause seems to be with incorrect Cypher generated, as captured in the summary screenshot above. It appears that KnowledgeGraphQueryEngine still has room to improve its Text2Cypher capability.
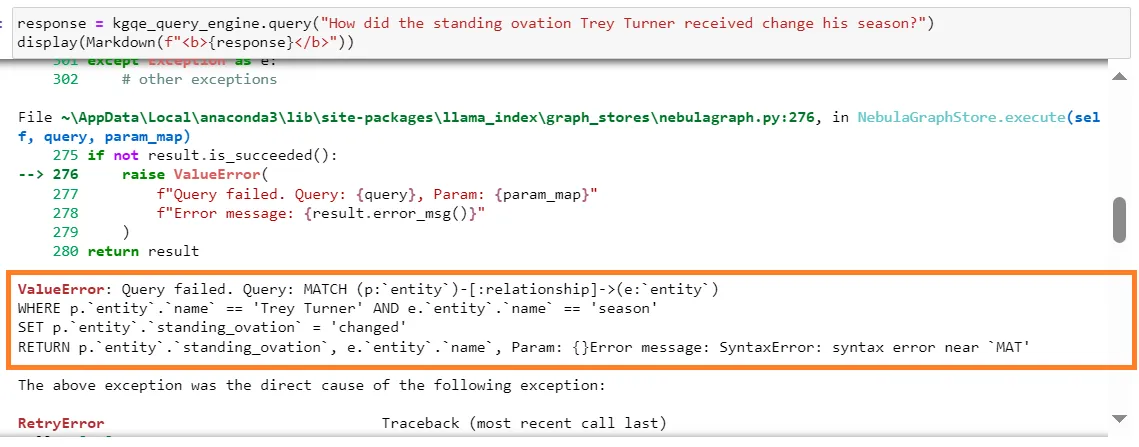
- KnowledgeGraphRAGRetriever returned a bare minimum response regarding the standing ovation event for Trea Turner. This response is less than ideal.
- The raw vector index retrieval returned a response much faster (~5 seconds) than the other KG query engines (10+ seconds), except the KG keyword-based entity retrieval (~6 seconds). The custom combo query engine was the slowest (~13 seconds). Based on the above observations for Question 2, with the comprehensive contextual data properly loaded into the knowledge graph, the KG vector-based entity retrieval seems to do a superior job than any other query engines mentioned above.
Question 3: Tell Me Some Facts About the Current Stadium of Philadelphia Phillies
See a list of responses for each of the seven query methods below:

Here’s my observation:
- The KG vector-based entity retrieval returned a decent response, with some historic background of the stadium.
- The keyword-based entity retrieval got it wrong. It didn’t even mention the name of the current stadium.
- The hybrid entity retrieval returned only the bare minimum facts about the current stadium, such as the name, year, and location. This begs the question of whether the embedding implementation in the KG index can be improved. I reached out to Wey, and he confirmed that there would be future enhancements to optimize the embedding-based KG index with native support of vector search in NebulaGraph. Awesome!
- The raw vector index retrieval returned some facts about the current stadium, similar to what hybrid entity retrieval returned.
- The custom comb query engine gave the best response, detailed and comprehensive, backed up by many statistics and facts on the stadium. It is by far the best response of all the query engines.
- KnowledgeGraphQueryEngine couldn’t find any facts about the current stadium of the Philadelphia Phillies based on the given context information. Again, it appears to be an issue with the auto-generated Cypher.
- KnowledgeGraphRAGRetriever couldn’t find any facts about the current stadium based on the given context information.
- The raw vector index retrieval returned a response much faster (~3 seconds) than the KG query engines (6+ seconds). The custom combo query engine was the slowest (~12 seconds).
Key Takeaways
Based on the experiments we did above to analyze three questions on seven query engines, let’s compare the pros and cons of the seven query engines side by side:
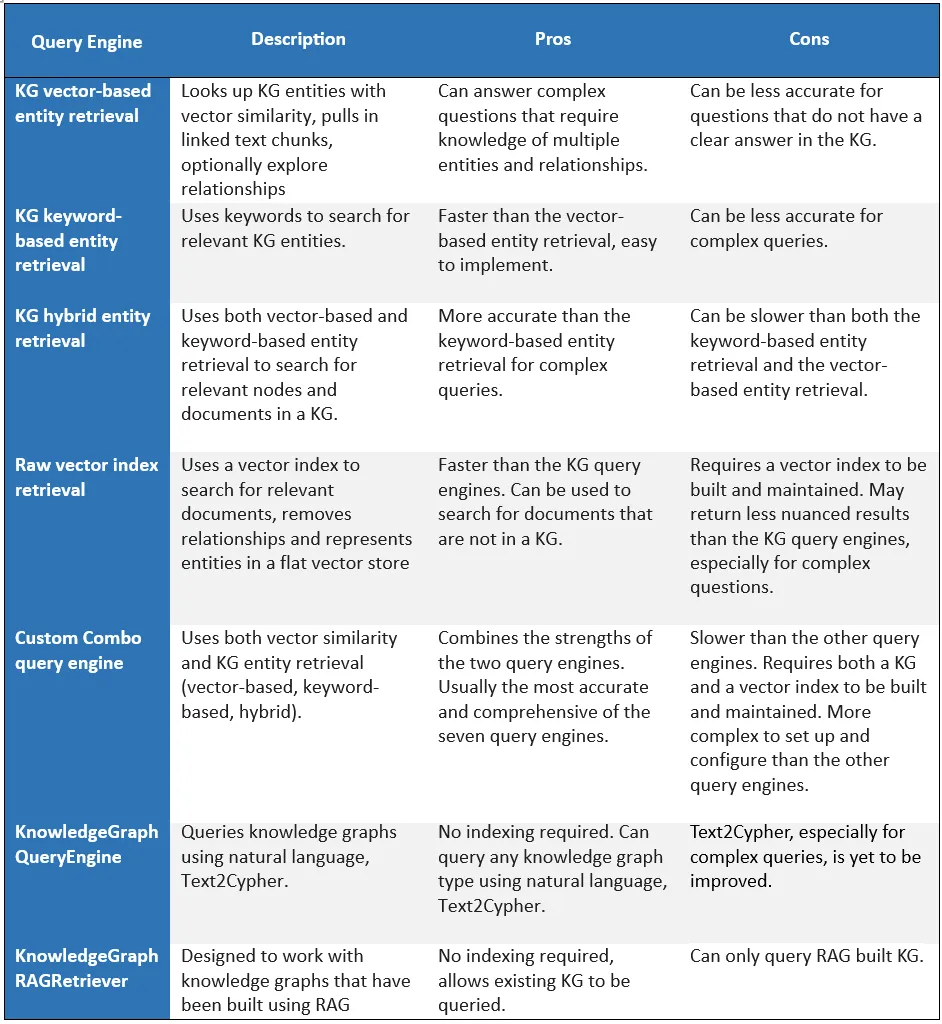
Which query engine is best for you will depend on your specific use case.
- If the knowledge pieces in your data source are spread and fine-grained, and you require complex reasoning over your data source, such as extracting entities and their relationships in a networked format, like in the case of fraud detection, social networking, supply chain management, then a knowledge graph query engine is a better choice. The KG query engine is also helpful when your embeddings generate false correlations, which contributes to hallucinations.
- If you require similarity search, such as finding all of the nodes that are similar to a given node or finding all the nodes closest to a given node in a vector space, then a vector query engine may be your best choice.
- If you need a query engine that can respond to queries quickly, then a vector query engine may be a better choice, as they are typically faster than KG query engines. Even without embeddings, the extraction of the task (sub-job running on a single storage service in NebulaGraph) may be the main step that contributed to the latency in KG query engines.
- If you need the best quality responses, then the custom combo query engine, which combines the strength of both KG query engines and vector query engines, is your best bet.
Summary
We explored Knowledge Graph, specifically NebulaGraph, in this article. We built an RAG pipeline using LlamaIndex, NebulaGraph, and GPT-3.5 for the Philadelphia Phillies.
We explored the seven query engines, studied their inner workings, and observed their responses to the three questions. We compared the pros and cons of each query engine and better understood the use cases each query engine is designed for.
I hope you find this article helpful.
For the complete Jupyter notebook for our Phillies’ RAG pipeline, refer to my GitHub repo.
Happy coding!
Published at DZone with permission of Wenqi Glantz. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments