Five Hard Problems in Vector Search, and How We Solved Them in Cassandra
Vector search is a critical component of generative AI tooling. Learn the five problems to consider and approaches to solving them when selecting one.
Join the DZone community and get the full member experience.
Join For FreeVector search is a critical component of generative AI tooling because of how retrieval augmented generation (RAG) like FLARE helps LLMs incorporate up-to-date, customized information while avoiding hallucinations. At the same time, vector search is a feature, not a product — you need to query vectors as they relate to the rest of your data, not in isolation, and you shouldn’t need to build a pipeline to sync the rest of your data with a vector store to do that.
2023 has seen an explosion in vector search products and projects, making selecting among them a serious effort. As you research the options, you’ll need to consider the following hard problems and the different approaches to solving them. Here, I’ll walk you through these challenges and describe how DataStax tackled them for our implementation of vector search for DataStax Astra DB and Apache Cassandra.
The Curse of Dimensionality
At the core of these hard problems lies what researchers call “the curse of dimensionality.” What this means in practice is that algorithms that work for exact vector search in 2-D or 3-D space, like K-D trees, fall apart when you get to 10s, 100s, or 1000s of dimensions in your vectors. The result is that there is no shortcut for exact similarity search with high-dimensional vectors; to get logarithmic-time results, we need to use approximate nearest neighbor (ANN) algorithms, which bring with them challenges in the following areas.
Problem 1: Scale Out
Many vector search algorithms were designed for datasets that fit in memory on a single machine, and this is still the only scenario tested by ann-benchmarks. (Ann-benchmarks further restricts its testing to a single core!) This might be okay for academic work of a million documents or rows, but it’s been many years since that could be considered representative of real-world workloads.
As with any other domain, scale-out requires both replication and partitioning, as well as subsystems to handle replacing dead replicas, repairing them after a network partition, and so forth.
This was an easy one for us: scale-out replication is Cassandra’s bread and butter, and combining that with the new-in-Cassandra-5.0 SAI (Storage-Attached Indexing — see CEP-7 for how it works — and the SAI documentation for how to use it) gave our vector search implementation powerful scale-out capabilities effectively for free.
Problem 2: Efficient Garbage Collection
By “garbage collection,” I mean removing obsolete information from the index — cleaning out deleted rows, and dealing with rows whose indexed vector value has changed. This might not seem worth mentioning — it’s been a more or less solved problem for forty years in the relational database world — but vector indexes are unique.
The key problem is that all the algorithms we know of that provide both low-latency searches and high-recall results are graph-based. There are lots of other vector indexing algorithms available — FAISS implements many of them — but all of them are either too slow to build, too slow to search, or offer recall that’s too low (and sometimes all three!) to be a general-purpose solution. That’s why every production vector database that I know of uses a graph-based index, the simplest of which is HNSW. Hierarchical Navigable Small World graphs were introduced by Yury Malkov et al. in 2016; the paper is quite readable, and I highly recommend it. More on HNSW below.
The challenge with graph indexes is that you can’t just rip the old (vector-associated) node out when a row or document changes; if you do that more than a handful of times, your graph will no longer be able to perform its purpose of directing BFS (breadth-first search) toward areas of greater similarity to a query vector
So you’ll need to rebuild your indexes at some point to perform this garbage collection, but when — and how — do you organize it? If you always rebuild everything when changes are made, you will massively increase the physical writes performed; this is called write amplification. On the other hand, if you never rebuild, then you'll do extra work filtering out obsolete rows at query time (“read amplification”).
This is another problem space that Cassandra has been working on for years. Since SAI indexes are attached to the main storage lifecycle, they also participate in Cassandra compaction, which logarithmically increases the storage units to provide a healthy balance between reads and writes.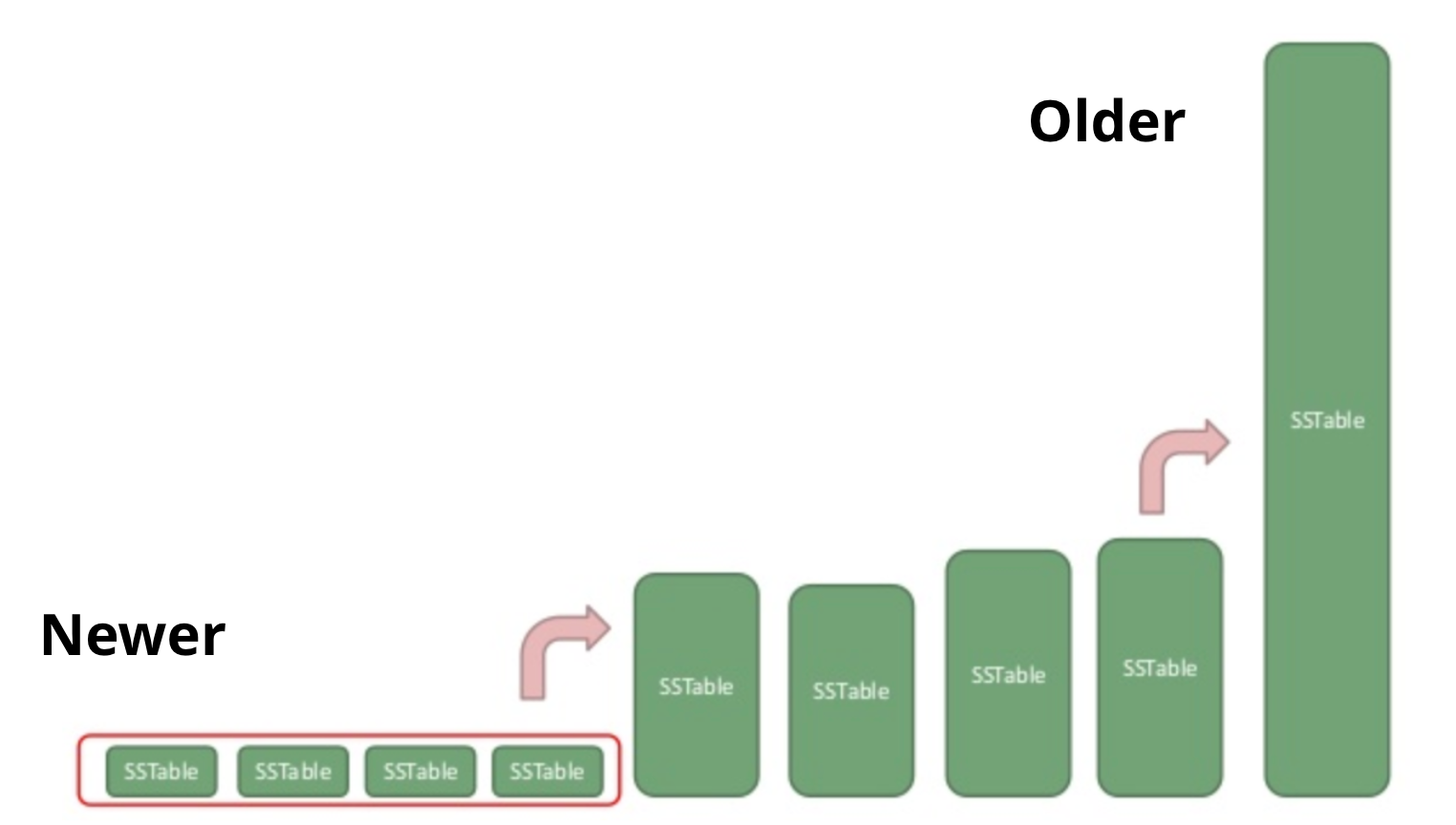
Sidebar: Cloud Application Workloads
DataStax Astra DB builds on Apache Cassandra to provide a platform for cloud application workloads. That means workloads that are:
- Massively concurrent thousands to millions of requests per second, usually to retrieve just a few rows apiece. This is why you couldn’t run Netflix on Snowflake, even if you could afford it: Snowflake and similar analytical systems are designed to handle only a few concurrent requests that each run for many seconds to minutes or even longer.
- Larger than memory. If your dataset fits in memory on a single machine, it almost doesn’t matter what tools you use. SQLite, MongoDB, MySQL — they’ll all work fine. Things get more challenging when that’s not the case — and the bad news is that vector embeddings are usually several KB or around an order of magnitude larger than typical database documents, so you’ll get to larger-than-memory relatively quickly.
- Core to the application. If you don’t care if you lose your data, either because it’s not that important or because you can rebuild it from the actual source of record, then again, it kind of doesn’t matter what tools you use. Databases like Cassandra and Astra DB are built to keep your data available and durable no matter what.
Problem 3: Concurrency
I mentioned above that the well-known ann-benchmarks comparison limits all algorithms to a single core. While this levels the playing field, it also handicaps those who can take advantage of the major source of hardware improvement over the last two decades.
A related problem is that ann-benchmarks only performs one type of operation at a time: first, it builds the index, then it queries it. Dealing with updates interleaved with searches is optional — and likely even a handicap; if you know that you don’t need to deal with updates, you can make a lot of simplifying assumptions that look good on artificial benchmarks.
If you care about being able to do multiple concurrent operations with your index or update it after it’s built, then you need to look a little deeper to understand how it works and what tradeoffs are involved.
First, all general-purpose vector databases that I know of use graph-based indexes. That’s because you can start querying a graph index as soon as the first vector is inserted. Most other options require you to either build the entire index before querying it or at least do a preliminary scan of the data to learn some statistical properties.
However, there are still important implementation details even within the graph index category. For example, we thought at first that we could save time by using Lucene’s HNSW index implementation, the way MongoDB Elastic and Solr do. But we quickly learned that Lucene only offers single-threaded, non-concurrent index construction. That is, you can neither query it as it is being built (which should be one of the primary reasons to use this data structure!) nor allow multiple threads to build it concurrently.
The HNSW paper suggests that a fine-grained locking approach can work, but we went one better and built a non-blocking index. This is open-sourced in JVector.
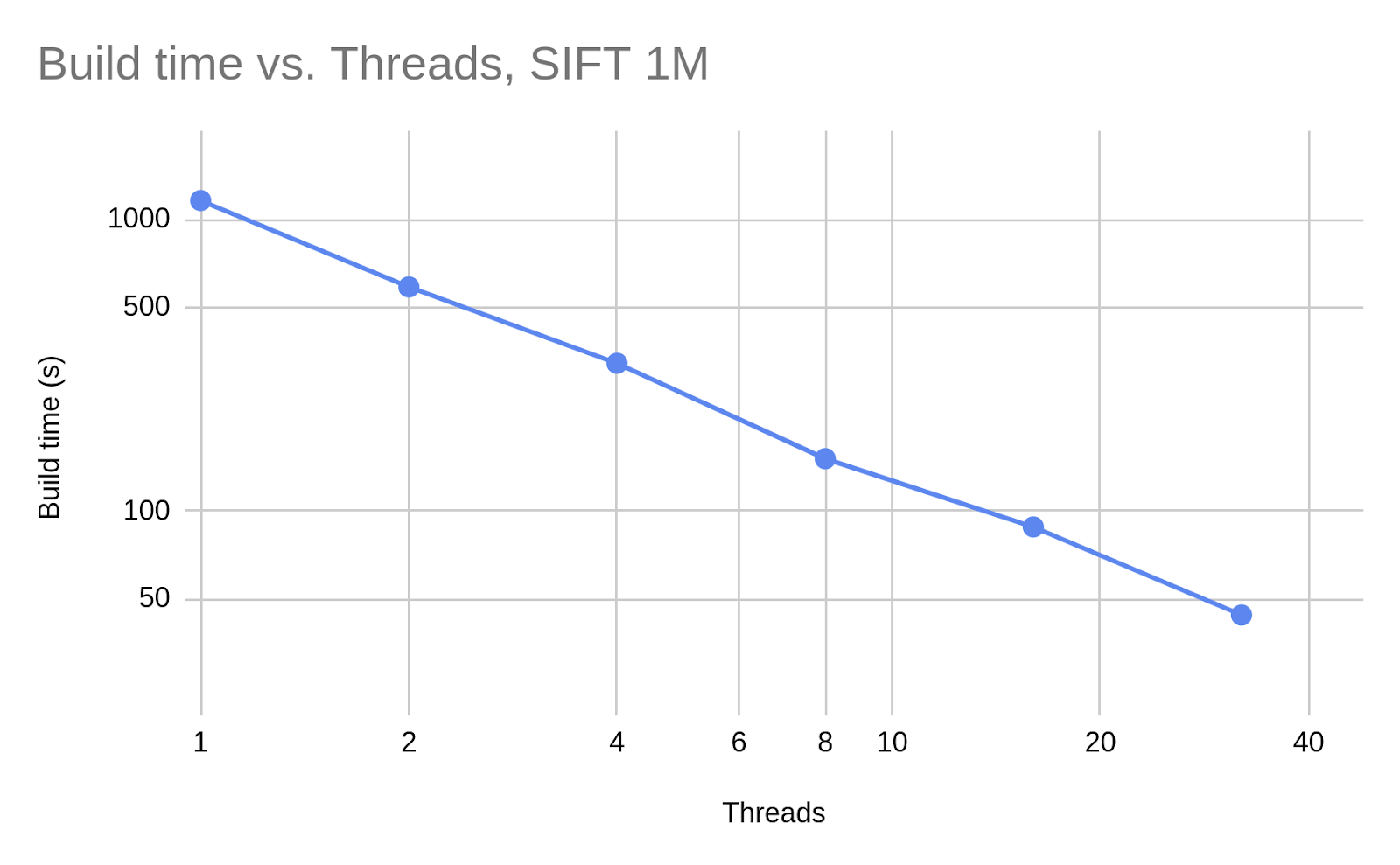
JVector scales concurrent updates linearly to at least 32 threads. This graph is log-scaled on both the x and y axes, showing that doubling the thread count halves the build time.
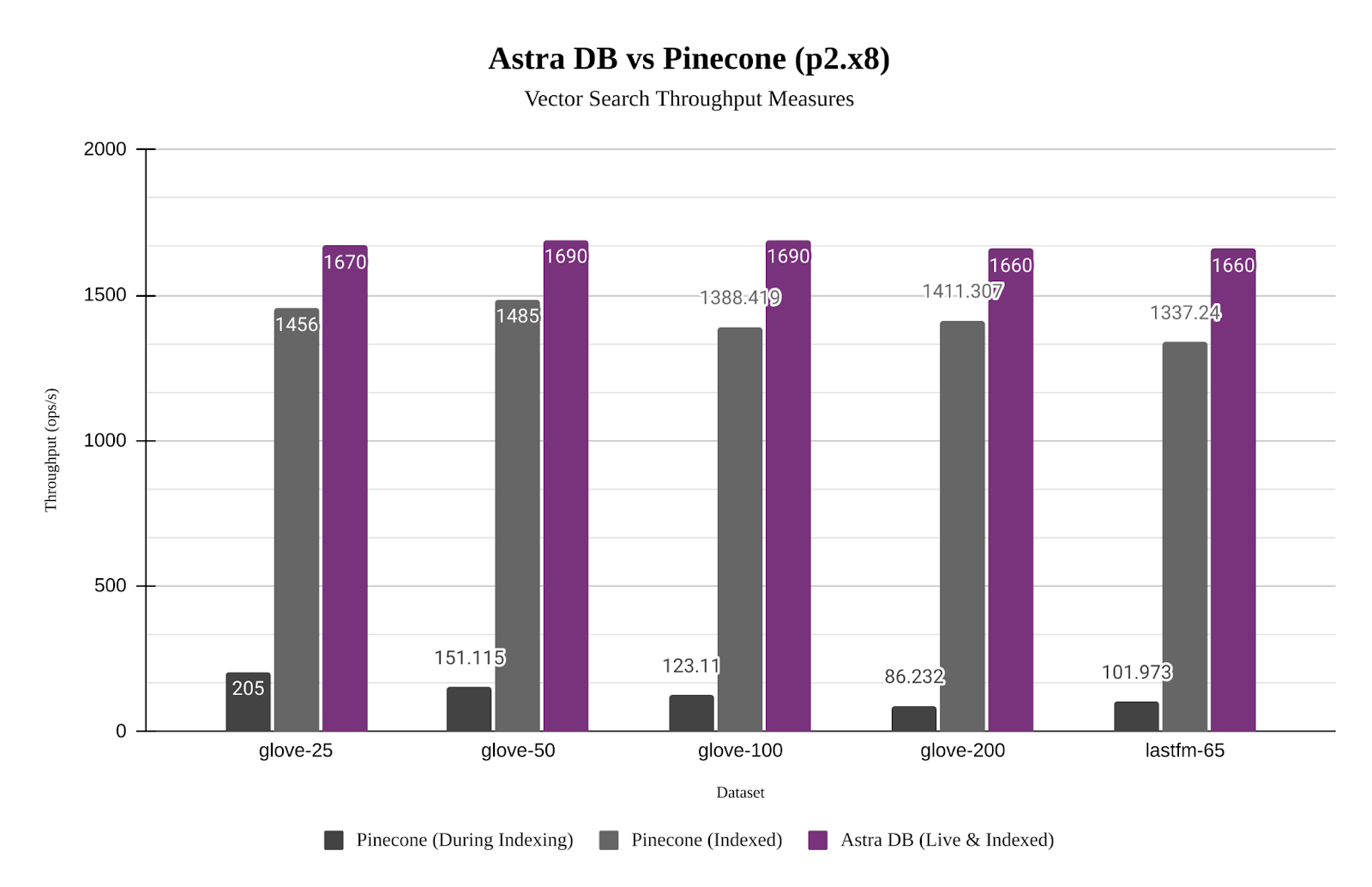
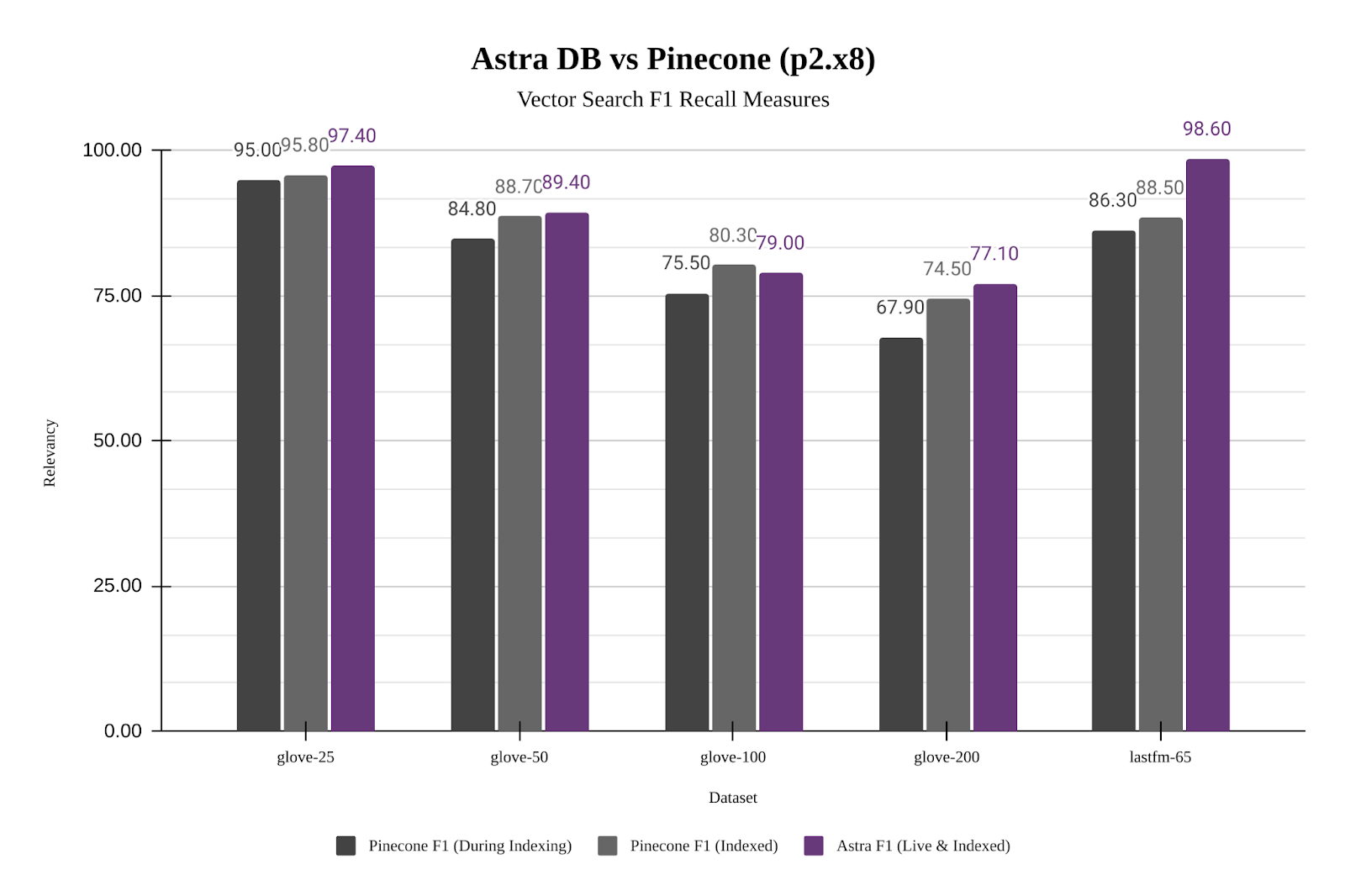
More importantly, JVector’s non-blocking concurrency benefits more realistic workloads by mixing searches with updates. Here is a comparison of Astra DB’s performance (using JVector) compared to Pinecone across different datasets. While Astra DB is about 10% faster than Pinecone for a static dataset, it is 8x to 15x faster while also indexing new data.
Astra DB does this while maintaining higher recall and precision as well:
Problem 4: Effective Use of Disk
We started with the HNSW graph indexing algorithm because it’s fast to build the index, fast to query, highly accurate, and straightforward to implement. However, it has a well-known downside: it requires a lot of memory.
An HNSW index is a series of layers, where each layer above the base layer has roughly 10% as many nodes as the previous. This enables the upper layers to act as a skip list, allowing the search to zero in on the right neighborhood of the bottom layer that contains all of the vectors.
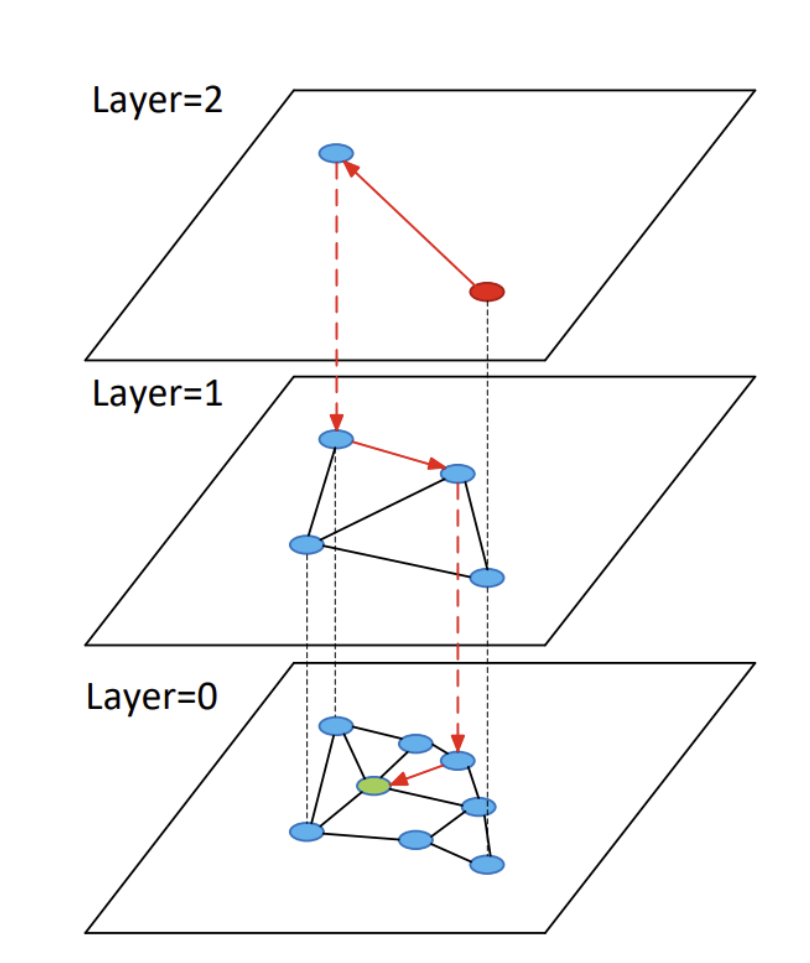
However, this design means that (in common with all graph indexes) you can’t get away with saying, “The disk cache will save us,” because, unlike normal database query workloads, every vector in the graph has an almost equal chance of being relevant to a search. (The exception is the upper layers, which we can and do cache.)
Here’s what a profile of serving a 100M vector dataset of Wikipedia article chunks (about 120GB on disk) looked like on my desktop with 64GB of RAM back when we were using Lucene:
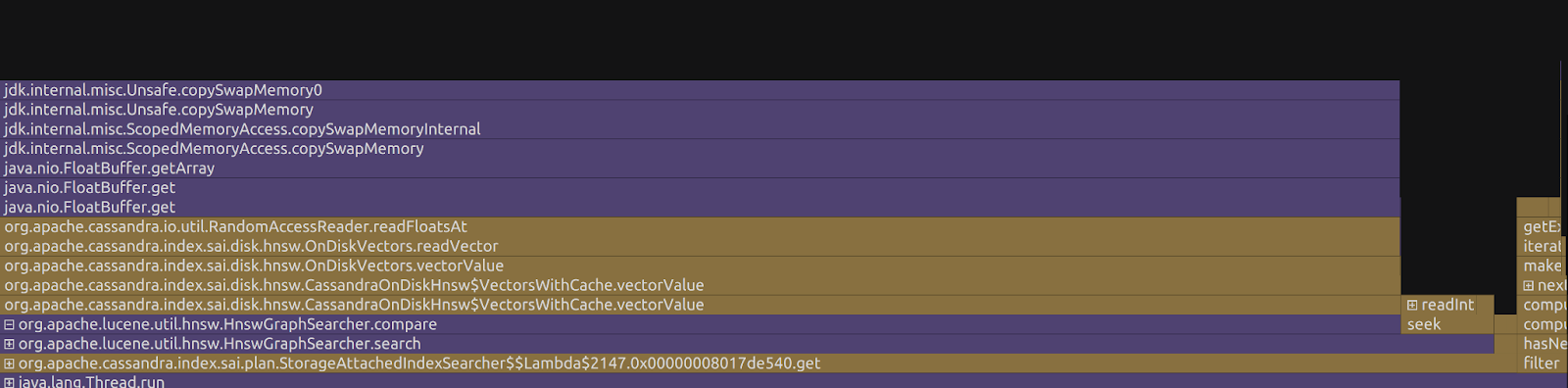
Cassandra is spending almost all of its time waiting to read vectors off of the disk.
To solve this problem, we implemented a more advanced algorithm called DiskANN and open-sourced it as a standalone embedded vector search engine, JVector. (Specifically, JVector implements the incremental version of DiskANN described in the FreshDiskANN paper.) Briefly, DiskANN uses a single-level graph with longer edges than HNSW and an optimized layout of vectors and neighbors to reduce disk IOPS and keeps a compressed representation of vectors in memory to speed up similarity computations. This results in tripling the throughput of the Wikipedia workload.
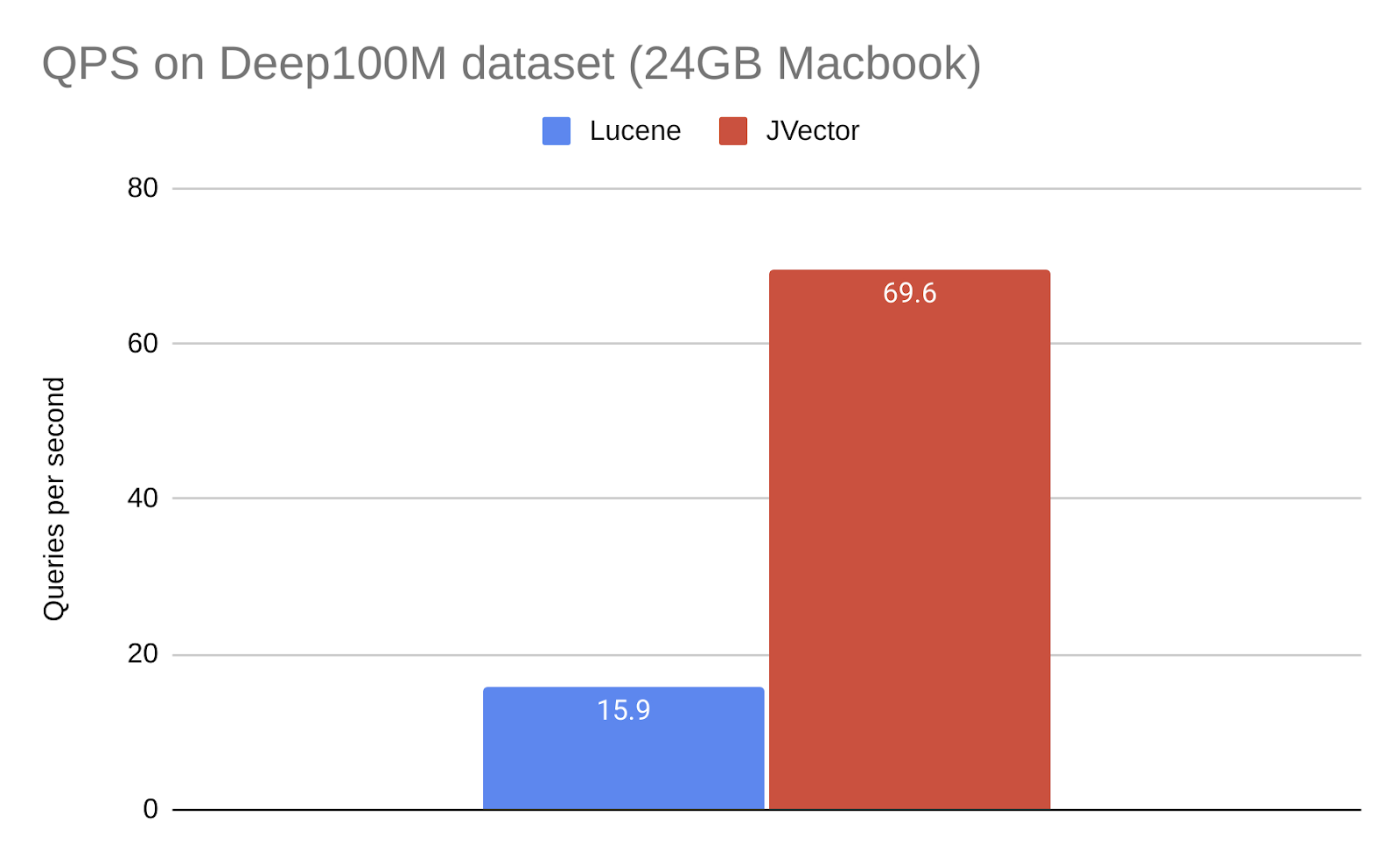
Here is what HNSW versus DiskANN looks like in a purely embedded scenario with no client/server components. This measures the speed of searching the Deep100M dataset under Lucene (HNSW) and JVector (DiskANN). The Lucene index is 55GB, including the index and the raw vectors. The JVector index is 64GB. The search was performed on my 24GB MacBook, which has about one-third as much memory as it would take to hold the index in RAM.
Problem 5: Composability
Composability in the context of database systems refers to the ability to seamlessly integrate various features and capabilities in a coherent manner. This is particularly significant when discussing the integration of a new category of capability, like vector search. Non-toy applications will always require both classic CRUD database features as well as the new vector search.
Consider the simple AI chatbot sample application for Astra DB. This is about as pure of a RAG application as you will find, using vector search to surface appropriate documentation to the LLM to respond to user questions. However, even a simple demo like this still needs to make “normal,” non-vector queries to Astra DB to retrieve the conversation history, which must also be included with every request to the LLM so that it can “remember” what has already taken place. So the key queries include:
- Find the most relevant documents (or document fragments) for the user’s question
- Retrieve the last twenty messages from the user’s conversation
In a more realistic use case, one of our solutions engineers was recently working with a company in Asia that wanted to add semantic search to their product catalog but also wanted to enable term-based matching. For example, if the user searches for [“red” ball valve], then they want to restrict the search to items whose description matches the term “red,” no matter how semantically similar the vector embeddings are. The key new query then (on top of classic functionality like session management, order history, and shopping cart updates) is thus: Restrict the products to those that contain all quoted terms, then find the most similar to the user’s search
This second example makes it clear that not only do applications need both classic query functionality and vector search, but they often need to be able to use elements of each in the same query.
The current state of the art in this young field is to try to do what I’m calling classic queries in a “normal” database, vector queries in a vector database, and then stitching the two together in an ad hoc fashion when both are required at the same time. This is error-prone, slow, and expensive; its only virtue is that you can make it work until you have a better solution.
In Astra DB, we’ve built (and open-sourced) a better solution on top of Cassandra SAI. Because SAI allows for creating custom index types that are all tied to the Cassandra Stable and compaction life cycle, it is straightforward for Astra DB to allow developers to mix and match boolean predicates, term-based search, and vector search, with no overhead of managing and synchronizing separate systems. This gives developers building generative AI applications more sophisticated query capabilities that drive greater productivity and faster time-to-market.
Conclusion
Vector search engines are an important new database feature with multiple architectural challenges, including scale-out, garbage collection, concurrency, effective use of disk, and composability. I believe that in building vector search for Astra DB, we have been able to leverage Cassandra’s capabilities to deliver a best-in-class experience for developers of generative AI applications. If you want to get up close and personal with vector search algorithms, check out JVector.
Published at DZone with permission of Jonathan Ellis. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments