360-Degree View of Data Platform Migration to GCP BigQuery
To unlock the potential of data, organizations must migrate or modernize their legacy data platforms to cloud-native solutions.
Join the DZone community and get the full member experience.
Join For FreeIn today's AI/ML revolution, data is the most valuable asset for organizations to succeed and outperform competitors. To unlock the potential of data, organizations must migrate or modernize their legacy data platforms to cloud-native solutions. Google Cloud Platform offers top-notch tools for running optimized data platforms. This article explores the migration process of big data platforms to Google Cloud BigQuery.
Migrating big data to Google Cloud BigQuery brings numerous benefits, including enhanced scalability, elasticity, and security. Although the process can be complex and time-consuming, it offers significant advantages. Various approaches exist for big data migration, and the ideal approach depends on the specific needs and requirements of each organization.
What Is Legacy Data Platform Migration?
Data platform migration encompasses the transfer of digital data from outdated on-premises repositories, including databases, data lakes, data warehouses, and computing environments, such as applications, data pipelines, ETL processes, and file ingestion jobs, to modern cloud infrastructure. This comprehensive process involves several stages: identifying and planning the migration, preparing the data, extracting it from legacy systems, performing any required transformations, and ultimately, transferring both the data and associated computational environments to the destination distributed cloud computing infrastructure.
Advantages of Data Platform Migration
Migrating a data platform to cloud infrastructure is a complex process, but it offers numerous benefits, including:
- Increased scalability: Cloud infrastructure provides virtually unlimited computing and storage resources, eliminating concerns about physical limitations and enabling access to large volumes of data.
- Elasticity: Organizations can dynamically provision computing resources on-demand, scaling them up or down as needed. This flexibility ensures optimal resource allocation during peak periods and reduces costs during periods of lower demand.
- Business continuity: Cloud backup solutions play a crucial role in maintaining uptime and ensuring business continuity. Organizations can leverage redundant computer resources without being constrained by geographical limitations, benefiting sectors like finance where downtime is not acceptable.
- Cost-effectiveness: Cloud migration offers cost savings compared to legacy on-premise infrastructure costs. Expenses such as real estate, utilities, hardware, software, support, and downtime are reduced, along with labor and depreciation costs.
- Convenience: By leveraging cloud service providers, organizations can focus on their core business while outsourcing infrastructure services. This convenience allows them to allocate resources to strategic initiatives rather than managing infrastructure.
- Sustainability: Cloud computing is more environmentally friendly than on-premises systems, reducing energy consumption and incorporating green features that minimize physical material usage.
By considering these advantages, organizations can make informed decisions regarding data platform migration to the cloud, aligning their operations with modern technological advancements and reaping the associated benefits.
Types of Data Platform Migrations
Data platform migration can be approached in different ways, depending on an organization's specific needs and requirements. Here are a few approaches that organizations can leverage:
Lift-and-Shift
The lift-and-shift approach involves migrating the entire infrastructure stack, including servers, databases, applications, and data, from the on-premises environment to the cloud without significant modifications. This approach offers several advantages:
- Minimal disruption to operations and functionality.
- Cost savings by avoiding the need to redesign or refactor applications.
- Quick execution without extensive reconfiguration or code modifications.
- Maintaining familiarity and compatibility with current systems.
- Retaining investments in software licenses and applications.
Refactoring Data Platforms
Refactoring involves transforming the data before migrating it to the cloud. This includes modifying data objects, ETL jobs, data pipelines, and connection configurations to make them compatible with cloud-based systems. Refactoring can lead to benefits in terms of performance, scalability, and security, but it requires custom utilities and validations.
New Cloud-Native Design
This approach, though more costly and time-intensive, offers organizations flexibility and control. It involves redesigning the data platform with cloud-native architectures and eliminating unused, outdated, and non-standard processes. This approach allows for the creation of more scalable, reliable, and highly available systems that align with current business needs.
By considering these different approaches, organizations can choose the most suitable one for their data platform migration, ensuring successful and optimized deployment in the cloud environment.
Data Platform Migration Planning
Let's examine the steps involved in data platform migration, including the associated tasks related to tables, schedules, consumers, and data producers.
![Data Platform Migration Planning]() Step 1: Define Migration Objective, Goals, KPIs, and Success Criteria
Step 1: Define Migration Objective, Goals, KPIs, and Success Criteria
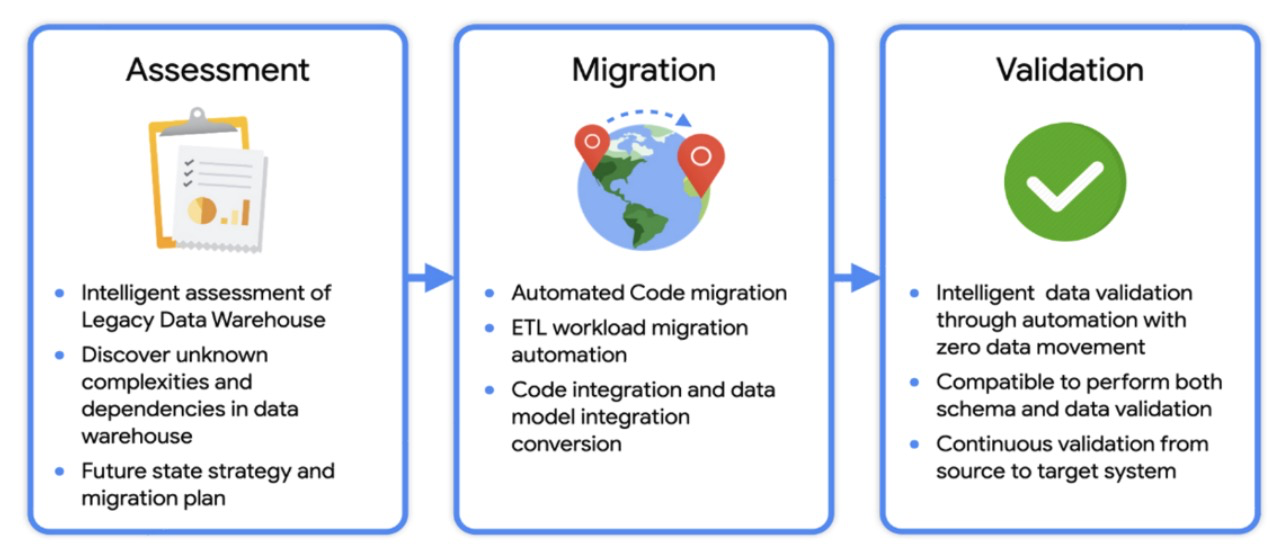 Step 1: Define Migration Objective, Goals, KPIs, and Success Criteria
Step 1: Define Migration Objective, Goals, KPIs, and Success CriteriaTo ensure a successful data platform migration, it's important to establish clear objectives, goals, and key performance indicators (KPIs). Defining success criteria helps measure the effectiveness of the migration. This step sets the foundation for the entire migration process.
Step 2: Assess the Existing Data Platform
A comprehensive assessment of the current data platform is crucial. This assessment should include an inventory of data and computational assets, such as data objects, data formats, and ETL pipelines. It's also important to identify stakeholders, including technology teams, business owners, data producers, and data consumers. Additionally, assess factors like SLAs, performance requirements, schedules, data standards, and compliance requirements.
Step 3: Decide on Migration Type and Design
Based on the organization's needs and requirements, select the appropriate migration approach. This decision could involve a combination of lift-and-shift, refactoring, or a new design approach. The chosen approach should consider factors such as data size, complexity, budget, and technical capabilities.
Step 4: Define the Roadmap with Milestones and Timelines
Create a detailed plan that includes milestones and timelines, considering both internal and external dependencies. It's important to map out the migration journey while taking into account potential impacts on day-to-day business operations. The roadmap provides a clear direction for the migration process.
Step 5: Obtain Sign-Off on the Migration Plan
Ensure that all parties involved in the migration, including stakeholders, project managers, and architects, review and approve the migration plan. This step ensures that everyone understands the plan, milestones, timelines, associated risks, and mitigation strategies before the migration begins.
By following these steps, organizations can effectively navigate the data platform migration process and increase the likelihood of a successful outcome.
Data Platform Migration Execution
Data Mapping
Understand the structure and format of the source data and map it to the appropriate structure in the target system. This ensures accurate data transformation during migration.
Data Extraction
Extract data from the source system or database, considering any dependencies or relationships that need to be maintained.
Data Transformation
Transform or convert data to meet the requirements of the target system. This may involve cleansing, reformatting, or restructuring the data.
Data Loading
Load the transformed data into the target system or database. This step may involve creating new tables, fields, or data structures as needed. It can include historical data loads, delta loads, real-time ingestions, and file-based ingestions.
Data Validation
Verify the accuracy and integrity of the migrated data. Perform data validation and testing processes to ensure completeness and consistency.
Cutover Process
After successfully completing and validating the data migration, transition to the new system or environment, discontinuing the use of the old system.
By following these steps, organizations can effectively execute a data platform migration, ensuring data integrity and a smooth transition to the new system.
Introduction to Google BigQuery
BigQuery is a powerful and fully managed data warehouse and analytics platform provided by Google Cloud. It offers a serverless and highly scalable solution for storing, querying, and analyzing large datasets in a fast and cost-effective manner. BigQuery is designed to handle massive amounts of data, enabling organizations to gain valuable insights and make data-driven decisions.
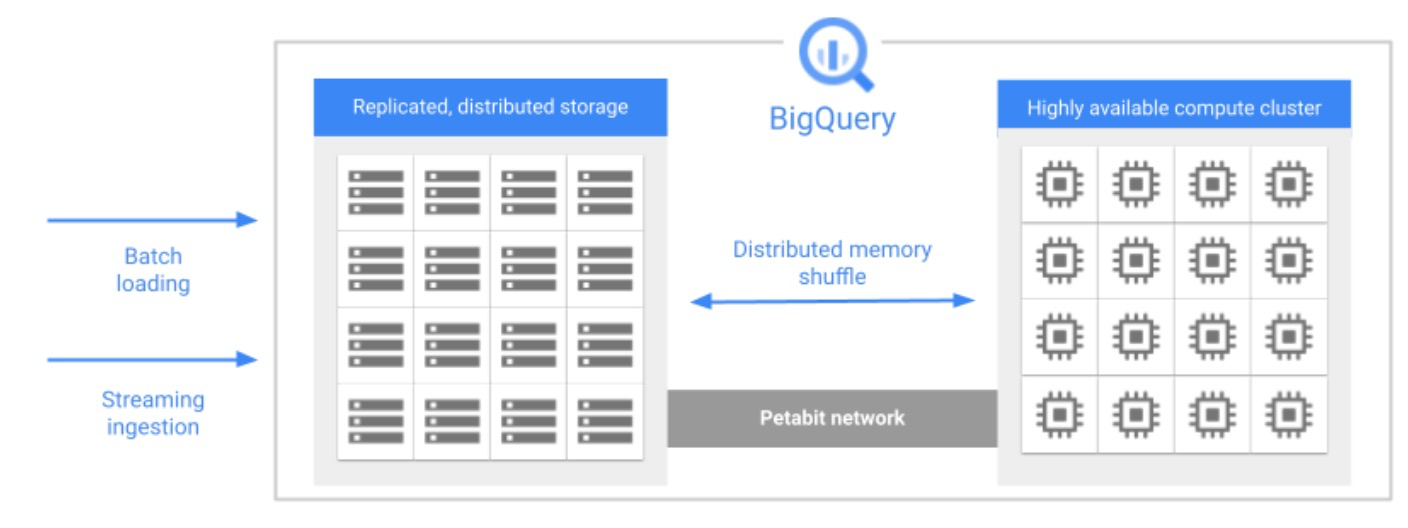
Key features and capabilities of BigQuery include:
- Data Storage: BigQuery provides a highly scalable and durable storage system that allows you to store structured, semi-structured, and unstructured data. It supports a variety of data formats, including CSV, JSON, Avro, Parquet, and more.
- Distributed Query Processing: BigQuery leverages a distributed architecture to process queries in parallel across multiple nodes. This enables high-performance querying even on large datasets. It automatically optimizes query execution and dynamically allocates resources based on the complexity and size of the query.
- SQL Query Language: BigQuery supports standard SQL, making it accessible to users familiar with SQL syntax. You can use familiar SQL constructs to query and manipulate data stored in BigQuery, making it easy to perform complex analytics tasks.
- Scalability and Elasticity: BigQuery offers automatic scaling of computational resources. It dynamically adjusts the allocated resources based on the query workload, ensuring optimal performance without manual intervention. This scalability allows BigQuery to handle both small and large-scale data processing requirements.
- Integration with Ecosystem: BigQuery integrates seamlessly with other Google Cloud services, such as Cloud Storage for data import/export, Cloud Dataflow for data processing, and Data Studio for data visualization. It also supports integration with popular business intelligence tools and frameworks, enabling easy integration into existing data workflows.
- Security and Governance: BigQuery provides robust security features, including encryption at rest and in transit, fine-grained access controls, and integration with Identity and Access Management (IAM) for managing user permissions. It also supports auditing and monitoring capabilities to ensure compliance with data governance policies.
- Cost Optimization: BigQuery operates on a pay-as-you-go model, allowing you to pay only for the resources you use. It offers flexible pricing options, including on-demand and flat-rate pricing, and provides cost optimization features such as data lifecycle management and query caching to minimize costs.
With its scalability, speed, and ease of use, BigQuery empowers organizations to unlock insights from their data and derive meaningful business intelligence. It is suitable for a wide range of use cases, including data analysis, ad hoc querying, real-time analytics, machine learning, and more.
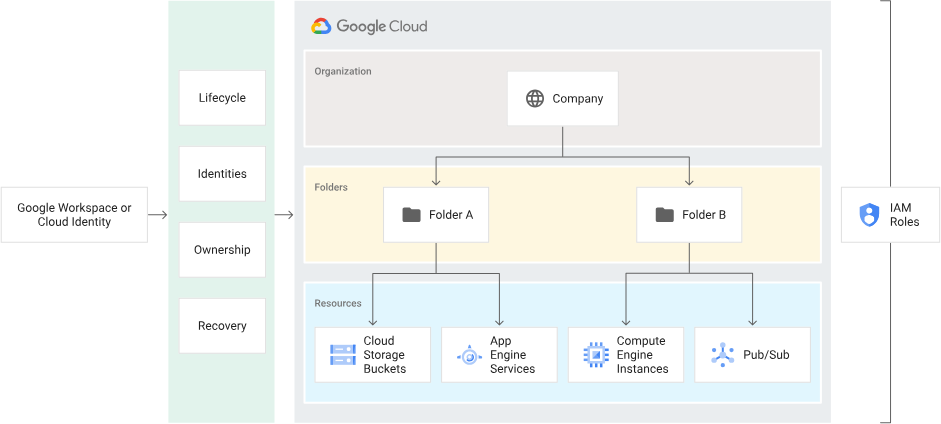
GCP Infrastructure Topology
The topology of the Google Cloud Infrastructure is a crucial foundation for the Data Platform, and architects and subject matter experts must carefully consider the best way to organize data across the enterprise. This involves thinking about data access patterns, managing access controls, data processing and consumption layers, adherence to enterprise standards and guidelines, data classification, and more.
In the Google Cloud Platform (GCP), all resources are managed using a resource hierarchy that includes Organization, Folders, Projects, and Resources. This hierarchical structure helps in organizing and managing resources efficiently within the cloud infrastructure. It provides a clear and structured way to define access controls, apply policies, and allocate resources to different teams or departments based on their specific needs and responsibilities.
By leveraging the resource hierarchy in GCP, organizations can effectively manage their data platform and ensure proper governance and control over their data assets. It allows for streamlined management of resources, improved security, and efficient collaboration among teams working on the Data Platform.
Enterprise Data Topology in Google BigQuery
Organizing data in Google BigQuery involves structuring and managing datasets, tables, and partitions effectively to optimize query performance and facilitate data analysis. Here are some key aspects of organizing data in BigQuery:
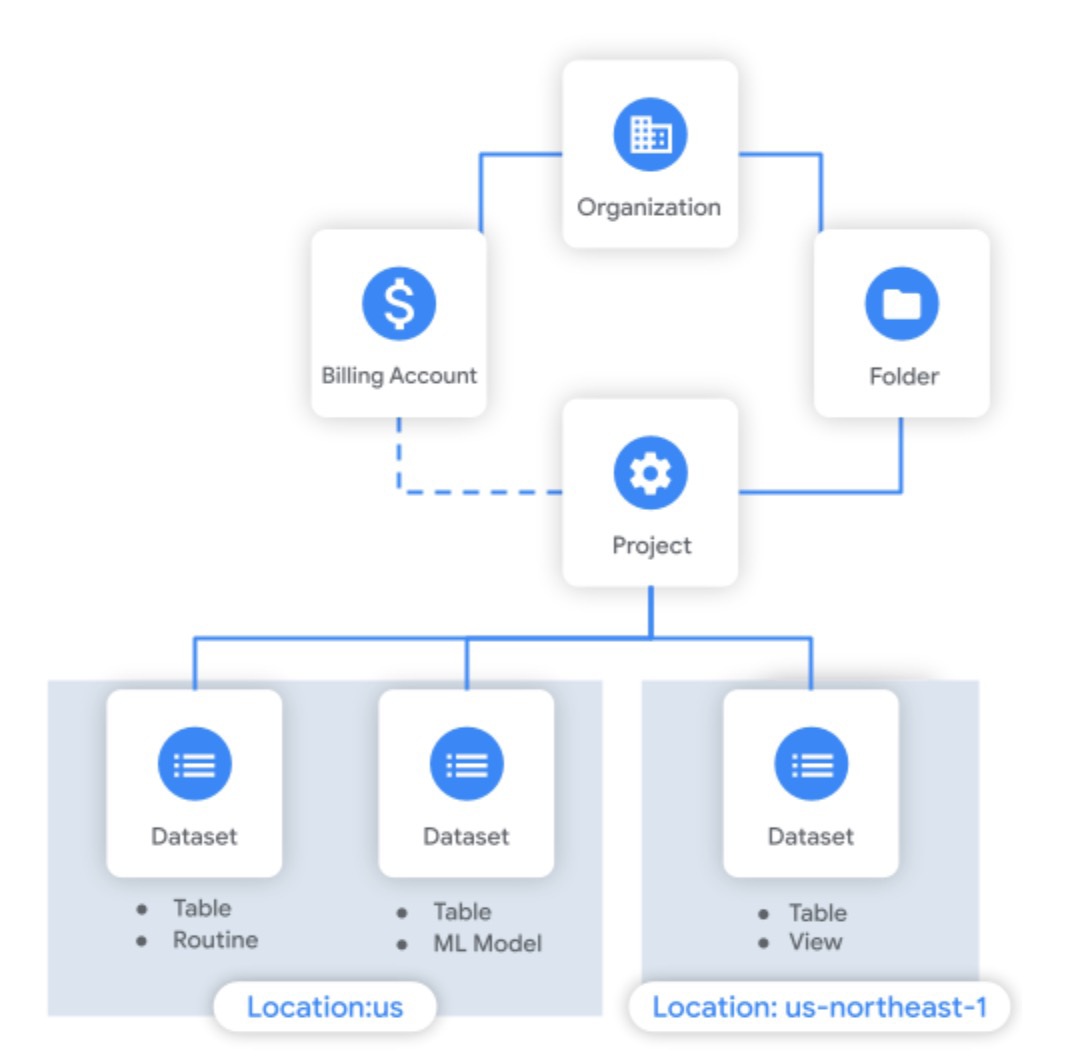
Datasets
BigQuery uses datasets as a logical container to organize and group related tables. Datasets provide a way to organize data based on projects, departments, or specific use cases. It is recommended to create separate datasets for different sets of data to improve manageability and access control.
Tables
Within datasets, tables store the actual data in BigQuery. When creating tables, it is essential to define the appropriate schema and choose suitable data types for each column. This ensures data integrity and facilitates efficient query processing. BigQuery supports various table types, including native tables, external tables, and partitioned tables.
Partitioned Tables
Partitioning is a technique to divide large tables into smaller, more manageable partitions based on a specific column such as date or timestamp. Partitioning can significantly improve query performance by limiting the amount of data that needs to be scanned during queries. It enables efficient data filtering and retrieval, especially when dealing with time-series or date-based data.
Clustering
Clustering is another technique to improve query performance by organizing data within partitions based on similar values in one or more columns. Clustering reduces the amount of data read during queries as it groups related rows together. It is particularly useful when querying specific subsets of data based on common attributes.
Views
BigQuery allows the creation of views, which are virtual tables that reference data from one or more source tables. Views provide a way to simplify complex queries, create reusable logic, and enforce data access controls. They can be used to abstract underlying table structures and present a simplified view of the data.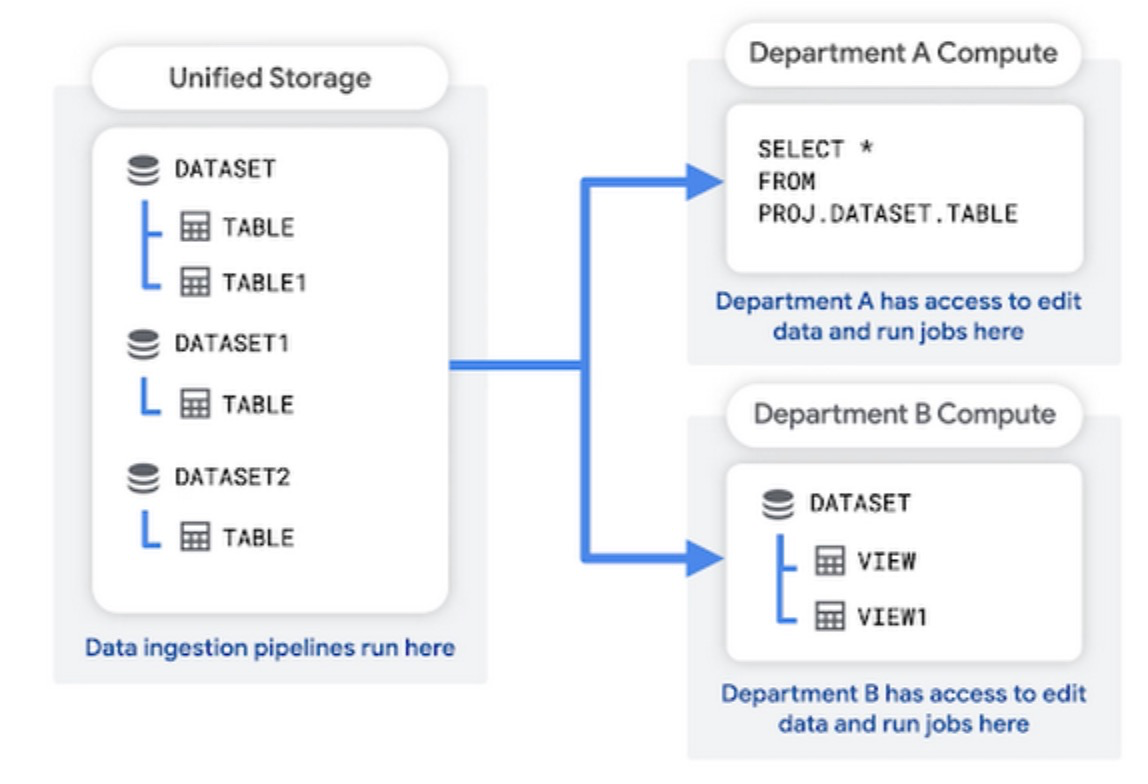
Data Lifecycle Management
BigQuery provides features for managing the lifecycle of data, including time-based data expiration and archiving. By setting appropriate expiration policies, you can automatically delete or move outdated or less frequently accessed data to lower-cost storage options, optimizing costs and performance.
Access Control
Proper access control is essential for maintaining data security and ensuring that only authorized users have appropriate permissions to access and modify datasets and tables. BigQuery integrates with Google Cloud's Identity and Access Management (IAM), allowing granular control over permissions and roles.
Organizing Enterprise Data in BigQuery
Big Picture of Enterprise Data
In large enterprise organizations, the Enterprise Data Architecture team faces the challenge of centralizing data assets and organizing them in Google BigQuery. They need to establish a scalable and reusable Data Platform that can handle the ingestion of data from diverse sources, including operational databases, real-time streaming, and file-based sources. This platform should be designed to accommodate the three V's of data: volume, velocity, and variety.
One crucial aspect is standardizing the processing of raw data collected from data producers. This involves applying transformations, cleansing, and enrichment to refine the data and make it suitable for consumption by data consumers within the organization.
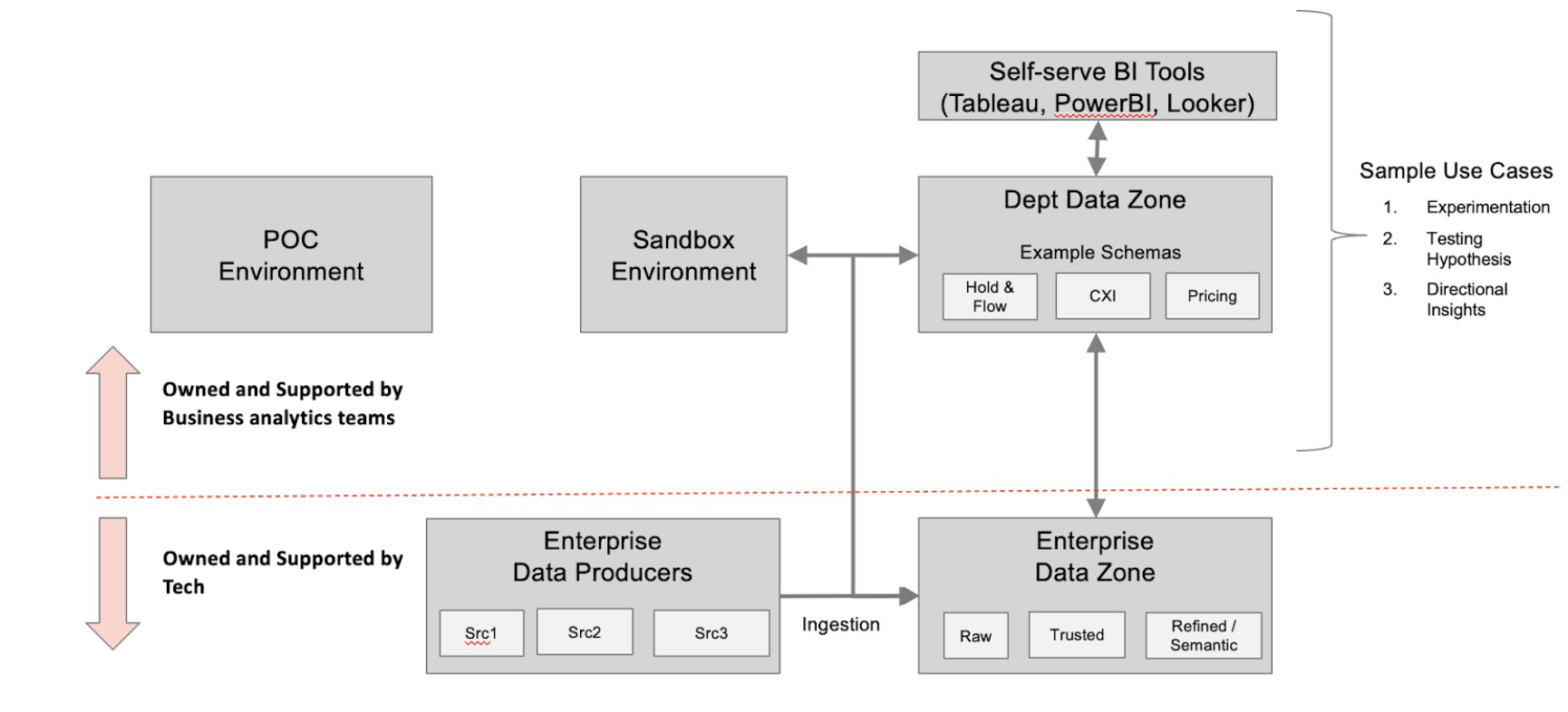
To effectively manage enterprise data, it is essential to categorize it into different zones based on its sensitivity, usage, or purpose. This can include zones such as raw data, curated data, or aggregated data. Access controls should be implemented to ensure that data is only accessible to authorized individuals or groups based on their roles and responsibilities.
Additionally, the Enterprise Data Architecture team should establish data consumption channels that align with the specific needs of different business units or departments within the organization. This can include providing self-service analytics tools, APIs, or data export capabilities to enable data consumers to retrieve and analyze the data in a manner that suits their requirements.
By addressing these challenges and implementing a well-designed Enterprise Data Architecture, organizations can effectively collect, organize, and govern their data assets in Google BigQuery, enabling data-driven decision-making, cross-functional collaboration, and maximizing the value of their data resources.
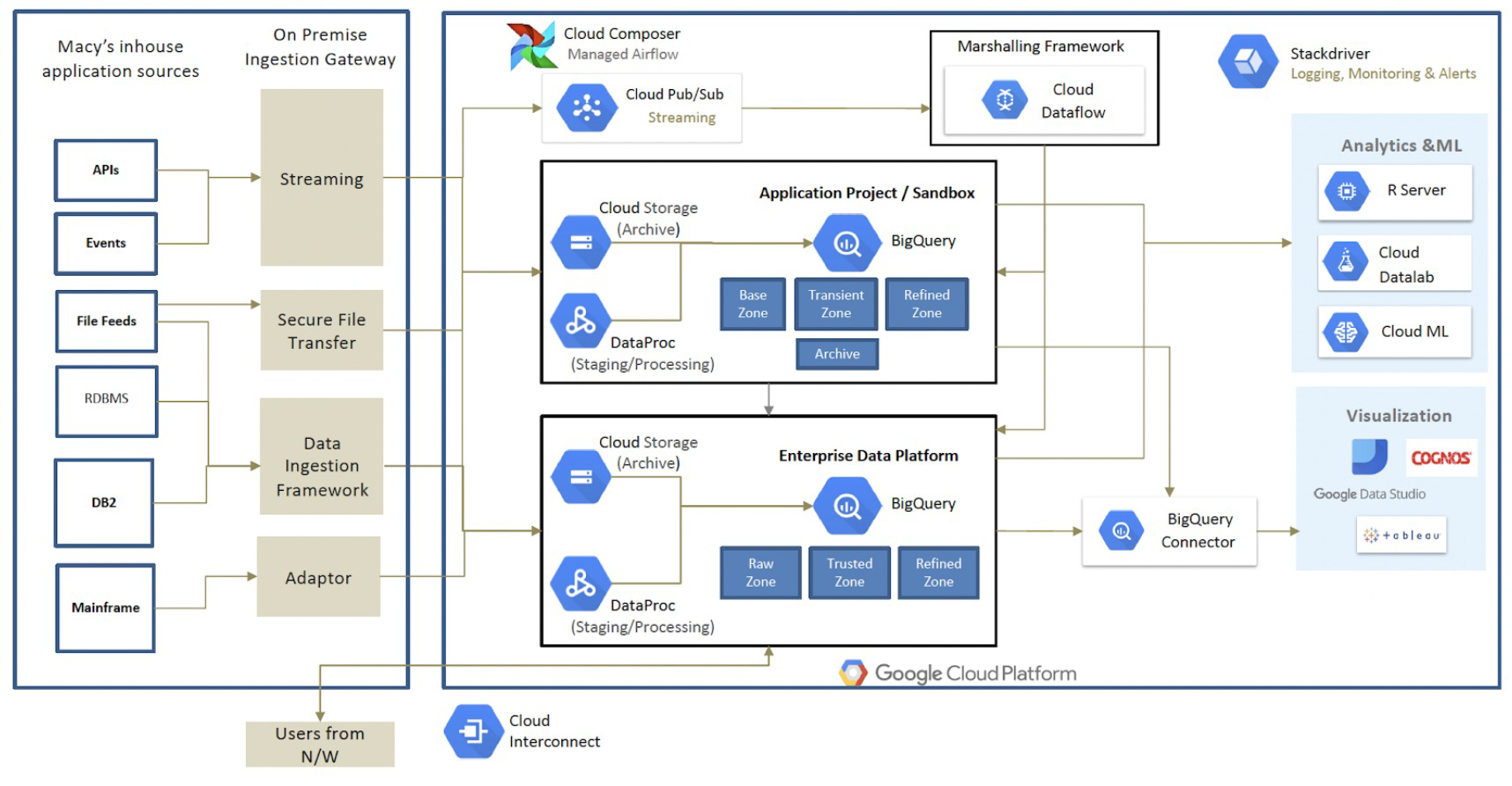
Data Ingestion
Data ingestion plays a crucial role in the collection and centralization of data, and it requires a solid and reliable Data Ingestion Framework (DIF) within an organization. The DIF should be highly available and provide configuration-driven and reusable ingestion patterns. These patterns should be easy to integrate and expand as needed.
It is essential to prioritize data security and privacy during the ingestion process. Organizations should establish a robust governance process to safeguard against any unauthorized data exposure or breaches. This includes implementing access controls, encryption, and monitoring mechanisms to ensure data protection.
Google Cloud Platform offers a range of services that can help build robust data ingestion pipelines into BigQuery. These services include:
- Google Cloud Storage (GCS): GCS provides scalable and durable storage for ingesting and staging data before it is loaded into BigQuery. It offers various ingestion methods, such as batch uploads or streaming data in real time.
- Pub/Sub: Pub/Sub is a messaging service that enables reliable and scalable data streaming. It can be used to ingest real-time data from various sources and publish it to subscribers, which can then be processed and loaded into BigQuery.
- Cloud Composer (Apache Airflow): Cloud Composer is a fully managed workflow orchestration service based on Apache Airflow. It allows you to create and schedule complex data ingestion workflows, coordinating data movement and transformations before loading into BigQuery.
- DataProc: DataProc provides a managed Apache Hadoop and Apache Spark service. It can be leveraged for processing and transforming large volumes of data before loading it into BigQuery.
- DataFlow: DataFlow is a fully managed service for executing data processing pipelines. It supports both batch and stream processing, making it suitable for ingesting and transforming data before loading it into BigQuery.
- Cloud Functions: Cloud Functions allow you to run event-driven, serverless functions that various data ingestion events can trigger. It provides a flexible and scalable way to perform lightweight data transformations or enrichment before loading into BigQuery.
By leveraging these Google Cloud Platform services, organizations can build robust and scalable data ingestion pipelines, ensuring efficient and reliable data collection into BigQuery.
Data Processing
After ingesting data into BigQuery, the next critical step is processing the data. To establish a data processing standard, organizations can consider creating separate zones for different stages of processing. In a hypothetical use case, let's assume the following three zones for processing data:
- Raw Zone: In the Raw Zone, an exact replica of the source system data is stored and maintained. This zone includes two versions of the data. The historical version stores the entire history of the data, while the snapshot version aggregates the delta of the data as soon as it is received. This allows for the preservation of the original data and enables traceability.
- Trusted Zone: The Trusted Zone is where data proceeds according to the enterprise data standards and guidelines defined by the Data Governance teams. In this zone, data is cleansed, standardized, and transformed to ensure accuracy and consistency. It serves as a single source of truth for reliable and trusted data. Master and reference data can also be stored in this zone, providing a reliable foundation for downstream processes and analytics.
- Refined Zone: The Refined Zone contains aggregated, processed, and enriched data sets that are tailored for specific business use cases. This zone may include semantic layers, cross-domain views, and data models optimized for analytical purposes. The Refined Zone enables efficient and effective data analysis, reporting, and visualization, providing valuable insights to drive decision-making and business outcomes.
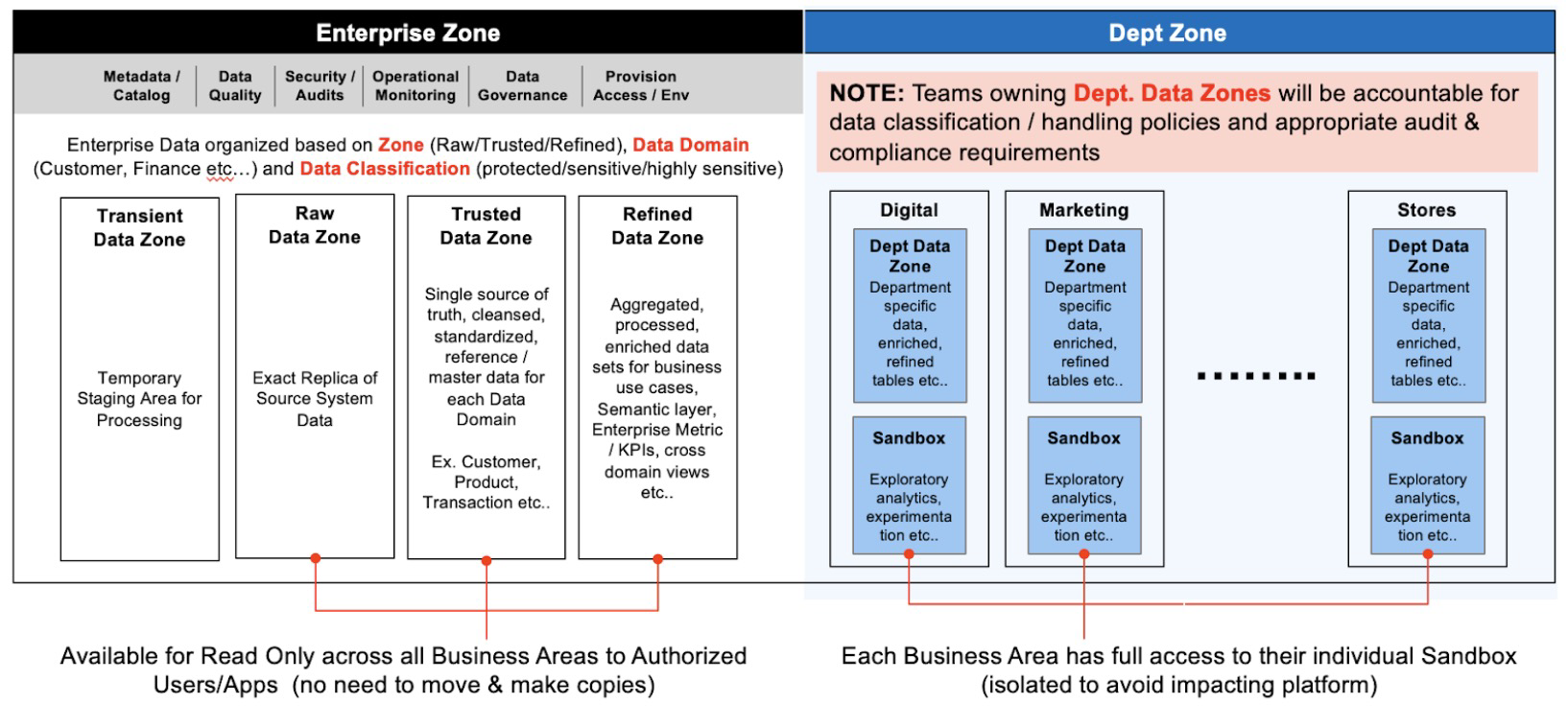 By establishing these separate processing zones, organizations can maintain data integrity, adhere to data governance standards, and support various data processing needs across the enterprise.
By establishing these separate processing zones, organizations can maintain data integrity, adhere to data governance standards, and support various data processing needs across the enterprise.
Data Consumption
Every department of an Organization would love to have access to the centralized enterprise data with the required processing and aggregations. Enterprise data architects must design data consumption layers with multiple integration options along with customization of consumer-specific requirements like enriched data sets for business use cases specific, cross-domain aggregated views, and semantic layers. This layer must have a provision to integrate with enterprise business intelligence, visualization tools, and secure file extracts exposed through APIs and streaming use cases. This layer must have strong security, access, audit, and compliance controls to protect data.
- A gigantic amount of data is available for capture in any organization. Make it available for decision-making, issue investigation, and assessing hypothesis and strategy
- Find nifty ways to comb through the data at lightning speed
- Become smarter about reducing the cost and resource usage for analysis and discovery operations
- Maximize data discovery and analysis time and minimize data collection and preparation time
- Identify manual data work and automate with the help of technology
- Be steps ahead of what consumers are going to ask - Anticipate and build by leveraging existing initiatives
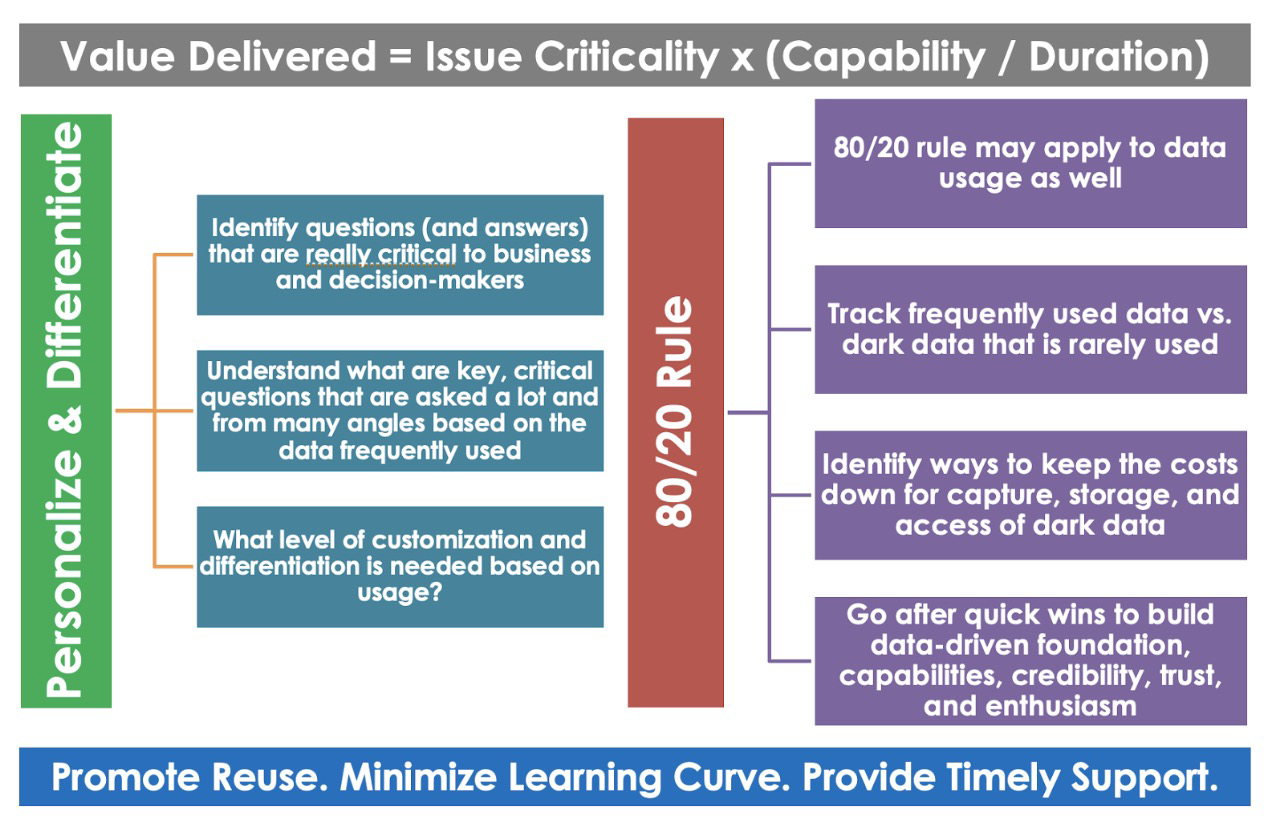
Data Democratization
Data democratization is the practice of providing universal access to data within an organization, enabling employees and stakeholders, regardless of their technical expertise, to gather and analyze data independently. It unlocks the value of organizational data, empowering individuals to identify opportunities, drive revenue, and enhance decision-making. By democratizing data, companies can stay ahead of the competition, capitalize on emerging trends, and ensure alignment throughout the organization.
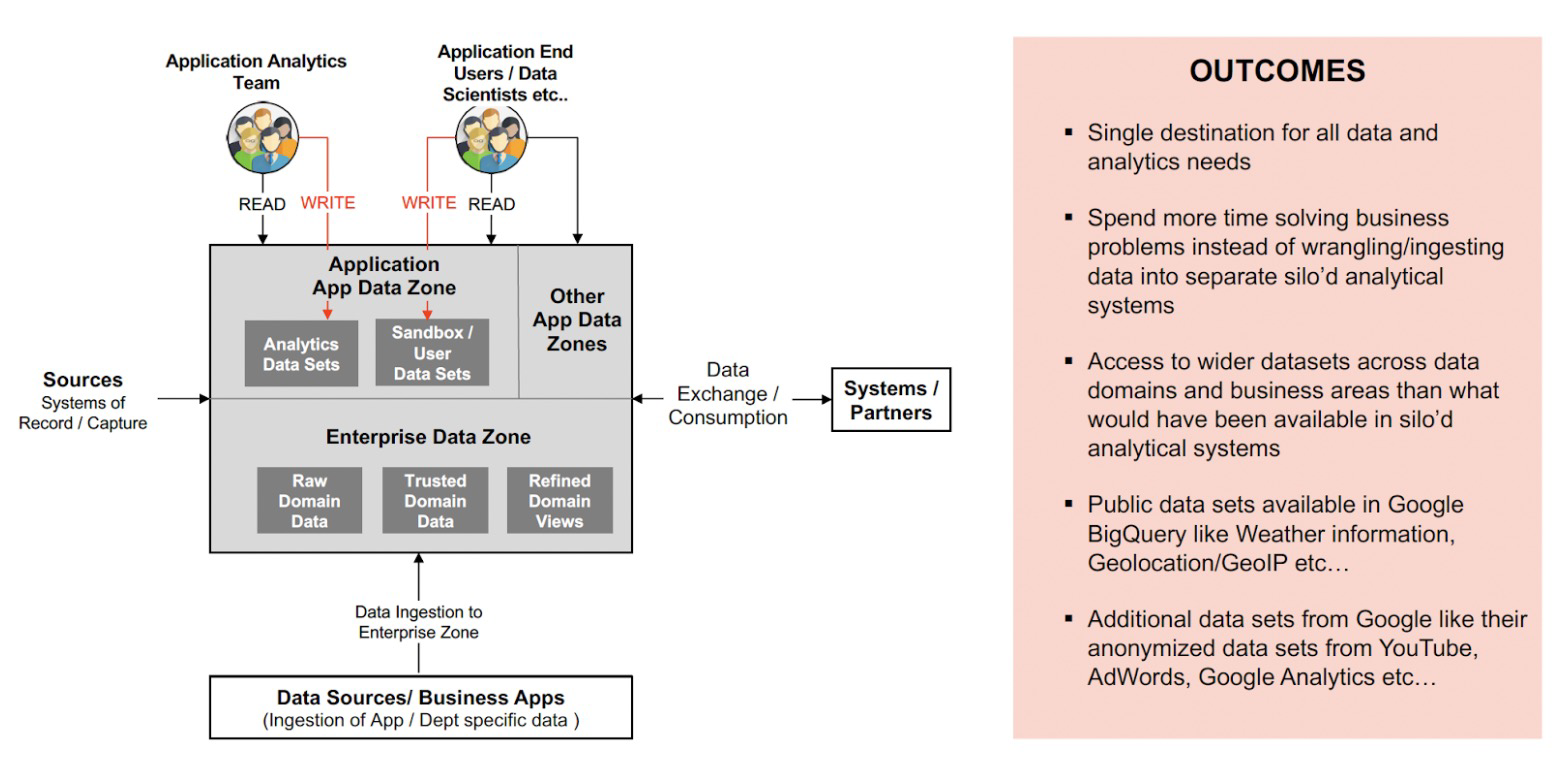
Migration of Data Platforms to Centralized data repositories like BigQuery enables access to wider datasets across the data domains, business areas, and google public data sets than the limited datasets available in siloed analytical systems.
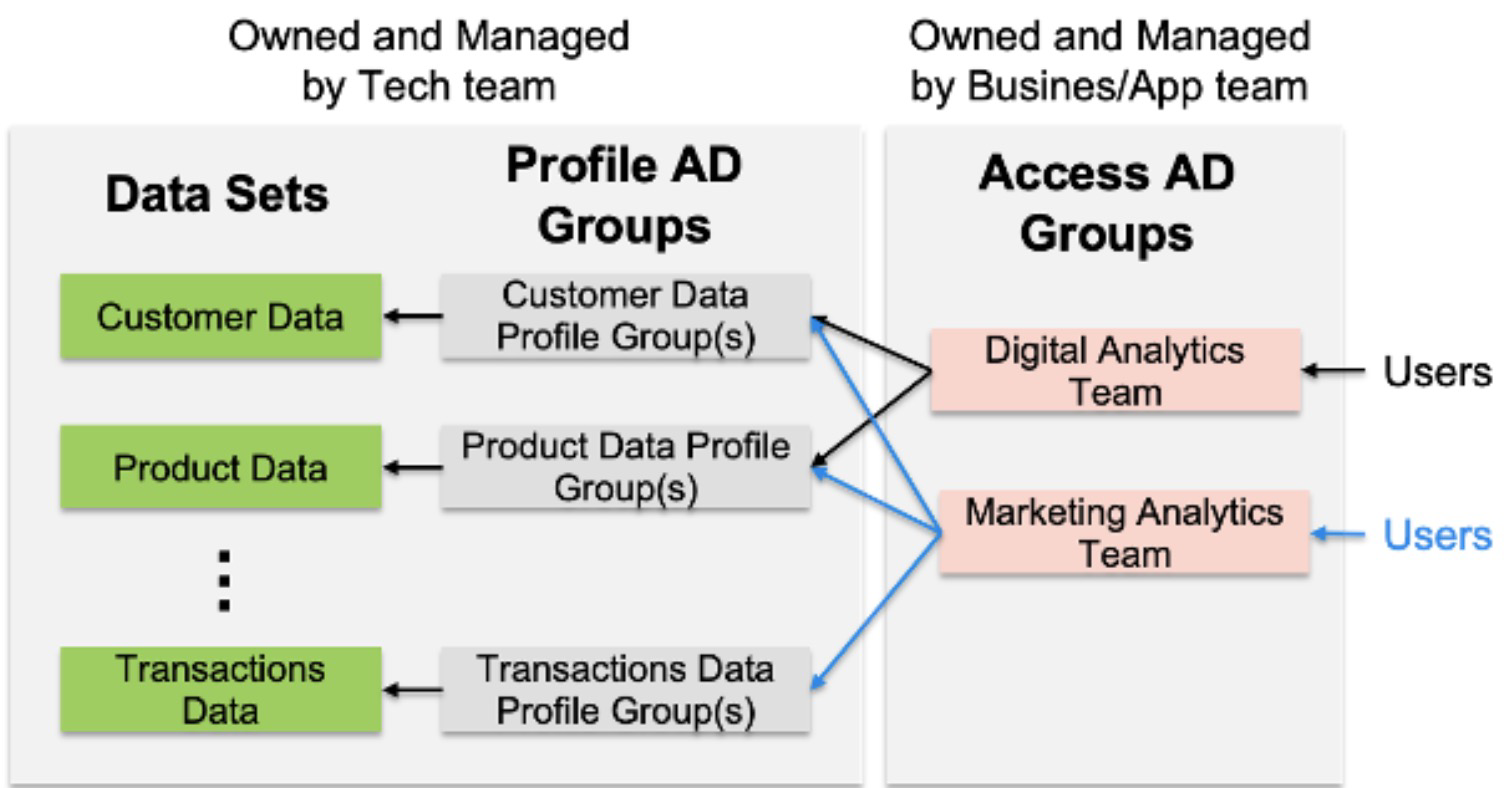
However, to avoid unwanted data exposure and data breaches, Organizations must leverage tight access controls and guard rails in the access provisioning process. There should be a separation of duties and separation of data based on the data classification.
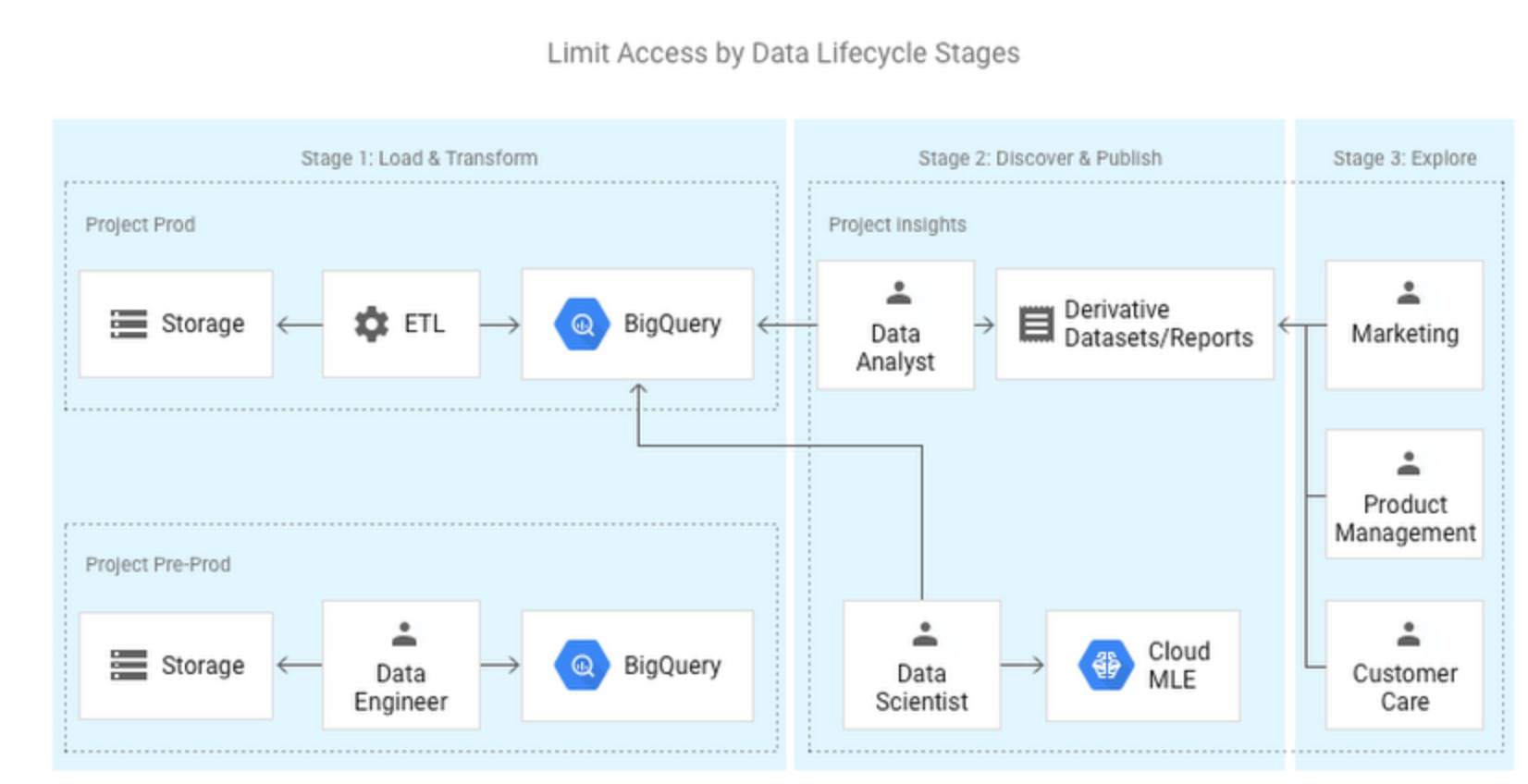
In BigQuery, this can be achieved through Identity Access Management (IAM) by defining roles, policies, and permissions assigned to the Principals (service accounts, Ad Groups, or Individual users). Enterprises can leverage their existing LDAP AD groups to define a group of users based on their shared data assets needs and provide access to them. Sample separation of data access based on domain and organizing through Profile groups and AD groups for application or business areas.
![Challenges in Migration]() Challenges in Migration
Challenges in Migration
 Challenges in Migration
Challenges in Migration- Assessing the current legacy environment can be a daunting task, especially when there is a lack of technical documentation and subject matter expertise.
- Identifying and establishing migration success criteria and assigning accountable ownership across departments.
- Ensuring adherence to data quality standards and guidelines for existing legacy data assets.
- Creating a reliable, reusable, and configuration-driven data ingestion framework is crucial for the success of the migration.
- Managing data effectively to enable data democratization presents significant challenges.
- Meeting audit, logging, and observability requirements during legacy migration can be complex.
- Controlling data proliferation and redundancy becomes more challenging as organizations grow in size.
- Enforcing data security measures to prevent unwanted data exposure and breaches.
- Maintaining data quality becomes increasingly difficult as data volume and computing requirements grow.
- Managing data processing costs on public cloud platforms is a key consideration.
- Ensuring business continuity and seamless day-to-day operations during the migration process can be delicate and time-consuming.
Opinions expressed by DZone contributors are their own.
Comments